-
Spring 프레임워크 - Spring Batch 아키텍처spring 2022. 9. 27. 00:08728x90반응형
Spring Batch 아키텍처
1. 배치 란?
가. 배치(Batch) 프로그램이란?
• 일괄적인 반복 처리작업
• 대부분 I/O에 대한 처리부터 내부적 비즈니스 로직 구현, Logging같은 부가기능까지 모두 개발자가 직접 개발이 필요.
나. 배치(Batch) 프로그램의 특징
• 사용자와의 상호 작용이 없다.
• 정해진 시간 제약 내에 실행이 완료 되어야 한다.
• 많은 자원이 소모되는 대용량 작업이다.
• 테스트가 어렵고, 테스트에 많은 시간이 소요된다.
2. 배치(Batch)시스템에 대한 대표적인 오해 (Pitfalls)
• 배치는 비교적 단순하고 덜 중요하다.
- 배치는 자동화된 대량 처리를 필요로 하는 온라인/정보계/대외계 모두와 밀접한 연관 관계를 갖고 있어 전사시스템이 유기적으로 업무를 처리하는 데 있어 촉매제와 같은 역할을 수행한다. (직접 사용자를 만족시키는 건 적으나, 부지런히 정보가 제때 처리되어야 한다.)
• 배치는 성능이 제일 중요하므로 C 같은 언어로 개발해야 한다
- 배치의 성능 최적화는 프로그래밍 언어나 프로그래밍 기법이 아닌 아키텍처 수준의 최적화를 통해 해결되어야 한다.
- 최적화 기법의 적용순서
* 배치업무 최적화 : 유사 업무 통합, 불필요한 반복 작업 제거
* 관리 고도화 : 수작업 데이터 검증최소화, 잘못된 결과로 재작업 최소화
* I/O 비용 최소화 : 배치 수행 시간의 80% 이상은 I/O 비용이며, I/O를 최소화 해야 최적화 된 성능 향상.
* 프로그램 최적화 : 일정 사이즈로 처리 데이터를 균일하게 Fetch해서 적정 횟수만큼 묶어 Commit. 프로그램 튜닝 팁 적용

3. Spring batch 란?
•Spring batch는 배치 어플리케이션의 표준화를 목적으로 탄생되었다.•보통, 배치 어플리케이션은 아래와 같은 작업을 수행한다.4. Spring batch 로 가능한 시나리오
•주기적으로 commit 이 발생하는 배치 프로세스를 처리할 때•동시에 N개의 같은 job을 돌려 병렬처리 하고 싶을 때•실패한 배치처리를 중간부터 다시 돌리고 싶을 때•배치 실행 이력을 남기고 싶을 때•기타 등등…모든 배치 시나리오를 spring batch로 가능하다.5. Spring batch 의 기술적 측면
- 배치가 실행되는 환경과 배치 업무 사이의 관심사를 분리한다.
- 개발자는 비즈니스 로직에 집중하고, 나머지는 프레임워크에서 처리한다.
- 배치 작업의 공통적인 부분을 핵심 인터페이스로 제공한다.(표준화)
- 핵심 인터페이스에 대한 default구현체를 제공해주어 쉽게 이용가능.
- 설정, 커스터마이징, 확장을 쉽게 할 수 있게 해준다.
6. Spring batch 아키텍쳐(구성)
•Application : 개발자가 spring batch 프레임워크를 사용해 코딩한 커스텀 코드 부분
•Batch Core : 배치 Job을 제어하고 실행시키는데 필요한 JobLauncher, Job, Step등을 포함한다.•Batch Infrastruncture : reader, writer, validator, retry, repeat 같은 서비스를 포함하며, 앞의 두 부분에서 사용한다.즉, Application과 Batch Core 모두 공통이 되는 인프라스트럭쳐 위에서 구축된다.7. Spring batch 를 사용하기 위한 준비
- Spring-batch-core가 Batch-infrastructure 의 dependency를 가지고 있으므로 Spring-batch-core만 설정해주면 된다.(필수)
- Spring batch test를 위해 추가
8. 일반적인 배치 어플리케이션에 대한 가이드 라인
•가능한한 단순화 하라. 단일 배치 안에서 복잡한 논리 구성을 피하라.•가능한 한 물리적 데이터에 가까운 곳에서 데이터를 처리하라.•I/O 리소스 사용을 최소화하고 가능한 한 internal 메모리를 사용하라.•배치 실행 안에서 같은 데이터를 두 번 처리하게 하지 마라.•데이터 무결성에 관해서는 항상 최악을 생각하라. 충분한 확인과레코드에 대한 validation 로직을 삽입하라.•테스트는 실제 상용 데이터 사이즈로 실제와 같은 환경에서 가능하면일찍 테스트 하라.9. Spring Batch 3.0 에서 추가된 기능
- JSR-352를 지원해서 표준배치스펙과 완벽하게 호환된다.
<?xml version="1.0" encoding="UTF-8"?>
<job id="myJob3" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="step1" >
<batchlet ref="testBatchlet" />
</step>
</job> -
Spring Batch Integration은 원래 Spring Batch Admin의 하위모듈이었는데 승격되어 spring batch 3.0부터 포함되었다.
-
Spring 4, Java8 지원 (최소 Java 6 이상에서 동작)
-
JobScope 지원 (기존에는 StepScope만 지원되었다.)
-
SQLite 지원
10. Step Scope

위의 코드는 컴파일시에 resource 값이 정해진다.
런타임시에 입력 받은 값을 resourc로 사용하고 싶다면? Late binding 이 필요하고 이를 가능하도록 스프링 배치에서는 step scope와 job scope를 제공해준다.

- Step scope : step scope로 설정된 빈은, step 실행이 시작 될때 생성된다
-
scope="step"은 스프링의 디폴트 설정이 아니기 때문에 반드시 명시적으로 설정해야한다.


11. Job Scope
•Step Scope와 유사하게 Job이 시작되기 전까지 scope="job" 으로 설정된 빈은 bean이 실제로 인스턴스화 될 수 없기 때문에 attribute의 late-binding이 가능하다.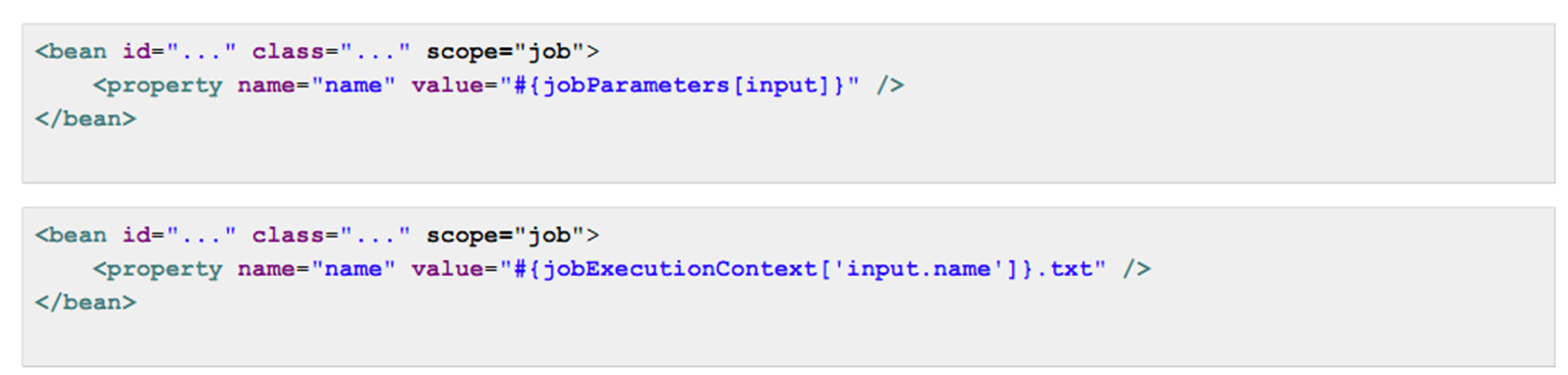 •scope=“job"은 스프링의 디폴트 설정이 아니기 때문에 반드시 명시적으로 설정해야한다.
•scope=“job"은 스프링의 디폴트 설정이 아니기 때문에 반드시 명시적으로 설정해야한다.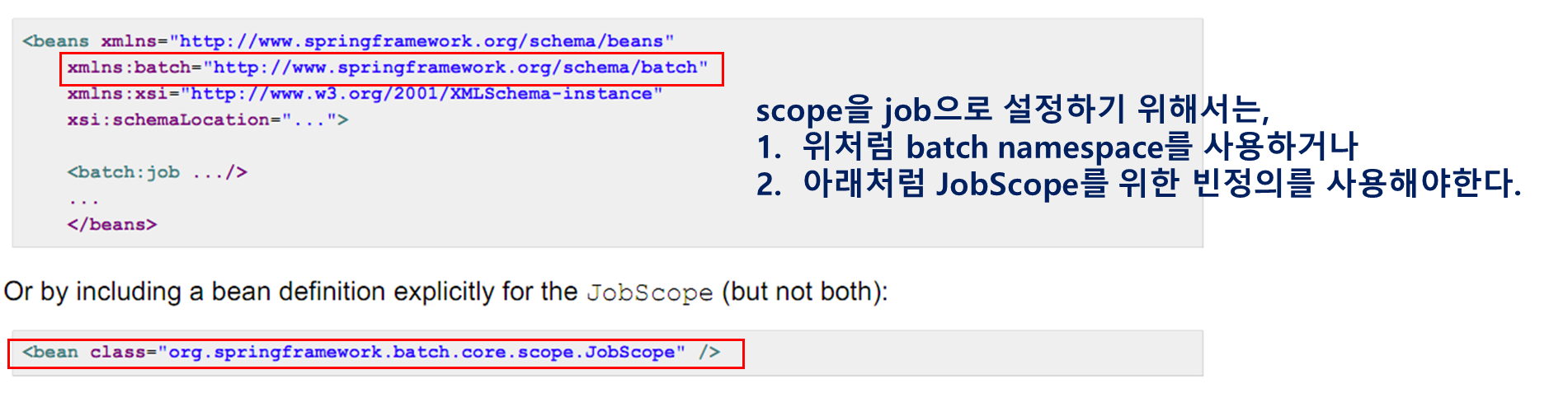

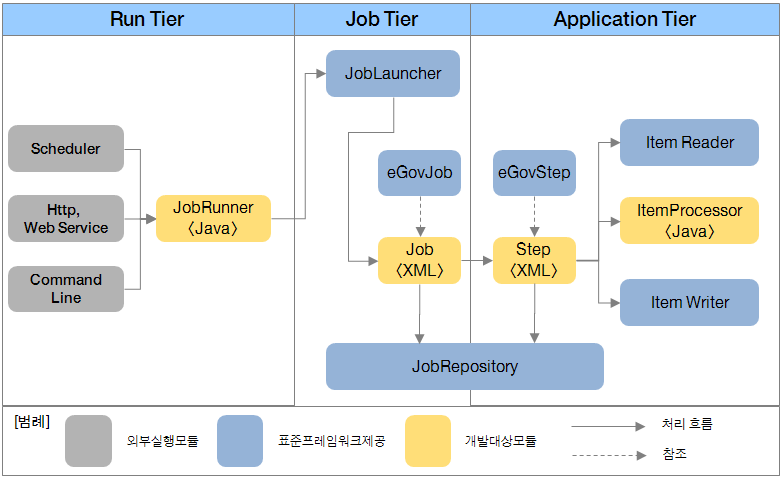
12. 배치 아키텍쳐의 단순화된 버젼
 •파란색 부분은 수십년 간 검증되어온 배치 아키텍쳐 부분•노란색 부분은 실제 배치 업무가 수행되는 부분
•파란색 부분은 수십년 간 검증되어온 배치 아키텍쳐 부분•노란색 부분은 실제 배치 업무가 수행되는 부분Spring batch도 이 배치 아키텍쳐를 기준으로 개발되었으며, 다이어그램에 나오는 배치 도메인 언어에 대한 개념 확실히 잡자.
13. Job 관련 배치 도메인
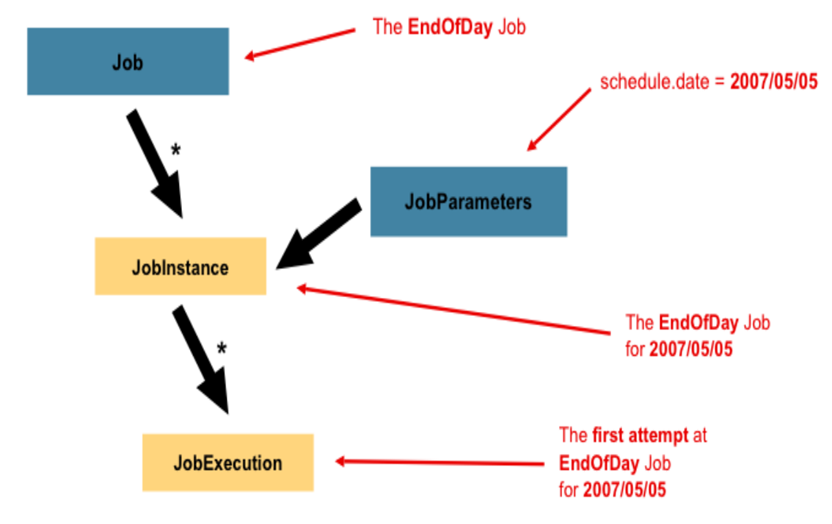
Job 배치 프로세스를 캡슐화한 엔티티로,
1개 이상의 Step을 담고 있는 컨테이너로 볼 수 있다.JobInstance Job 실행의 논리적인 개념을 의미한다.
매일 00시에 실행되는 EndOfDay Job을 보면, 2007/05/05의 실행과 2007/05/06의 실행은 각각 분리되어 추적 되어야 한다. 이를 가능하게 하는 논리적인 개념이 바로 JobInstance 이다.
(JobInsatnce = Job + JobParameters)JobParameters batch job을 시작시킬 때 사용한 파라미터의 집합으로,
그 쓰임새는 아래와 같다.
1.JobInstance를 식별하기 위해 사용2.Job 실행 동안 참조할 데이터로 사용JobExecution Job을 실행하는 한번의 시도를 의미한다.
실행은 성공 또는 실패로 끝날 수 있지만, 성공적으로 완료되지 않으면, 해당 JobInstance는 완료되지 않은 것으로 보고
재실행 시킬 수 있다. 재실행 시에는, JobInstnace는 생성되지 않고 기존의 것이 이용되지만 JobExecution 은 새로운 실행이므로 새로 생성된다.
또한 Job 실행 상태 및 지속되어야 할 속성들을 가지고 있으며 JobRepository를 통해 이 정보들이 db에 저장된다.JobExecution 객체가 가지고 있는 속성들
status 실행 상태를 나타내는 BatchStatus 객체이다.
COMPLETED, STARTING, STARTED, STOPPING, STOPPED, FAILED, ABANDONED, UNKNOWNstartTime Job 실행이 시작될 때의 시스템 시간(java.util.Date) endTime 성공/실패여부를 떠나 Job 실행이 끝났을 때의 시스템 시간(java.util.Date) exitStaus 실행결과를 의미하는 ExitStatus 객체로, job 실행을 호출한 caller에게 리턴 할
exit code를 가지고 있어 가장 중요한 속성이다.
(이 return된 값으로 caller는 재처리와 같은 다른 기능을 처리할 수도 있다.)createTime JobExecution이 생성 되었을 때의 시스템 타임(java.util.Date)
Job은 아직 시작되지 않았을 것이므로 startTime값은 없지만 항상 createTime은 존재한다. job 레벨의 executionContext 에서 이 값이 필요하므로 항상 생성된다.lastUpdated JobExecution객체가 존재했던 마지막 시스템 타임(java.util.Date) executionContext 실행 중 보관되어질 필요가 있는 사용자 data 를 담고 있는 보관소이다. failureExceptions Job 실행 동안 발생한 exception 목록이다. 이 속성들은 job 실행의 존재와 상태를 결정하는데 사용되므로 아주 중요하다.
1.1월1일에 EndOfJob 이 PM 9시에 실행되어 PM 9:30에 실패하였다면, batch meta-data table에는 아래와 같은 값이 들어가 있을 것이다.●2.다음날 실행 시에 실패한 job 이 다시 실행되고, 당일의 배치 job도 또한 실행되면 아래와 같은 결과가 남는다.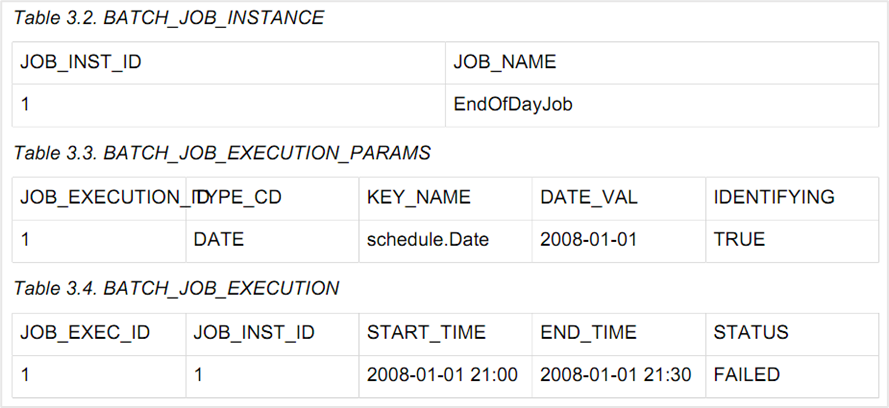


14. Step 관련 배치 도메인

Step 독립적, 순차적인 batch job의 단계를 캡슐화한 domain 객체,
실제 batch processing을 정의하고 컨트롤하기 위해 필요한 모든 정보를 담고 있다. 즉 step안에 실제 배치 업무가 담긴다.StepExecution step을 실행하는 한번의 시도를 의미하며, step이 시작될 때 마다 매번 생성된다. Job에 여러 개의 step이 정의되어 있는 경우, 어떤 step이 실패하면 그 다음에 실행될 step도 시작되지 않는다. StepExecution객체가 가진 속성들
status 실행 상태를 나타내는 BatchStatus 객체 startTime 실행 시작 시간(java.util.Date 형식) endTime 실행이 성공했든 실패했든 실행이 끝난 시간(java.util.Date 형식) exitStatus 실행 결과를 나타내는 ExitStatus 객체
caller에게 반환할 exit code를 가지고 있기 때문에 가장 중요하다.executionContext 실행 동안 보존될 필요가 있는 사용자 data를 담고 있는 객체 readCount 성공적으로 읽혀진 item 개수 writeCount 성공적으로 쓰여진 item 개수 commitCount 실행하는 동안 커밋 된 transaction의 수 rollbackCount 실행하는 동안 롤백된 transaction의 수 readSkipCount read 실패시 skip 갯수 processSkipCount process 실패시 skip 갯수 filterCount ItemProcessor에 의해 filter된 item 의 개수 writeSkipCount write 실패시 skip 갯수 15. ExecutionContext
가.개발자가 StepExection 이나 JobExectuion 의 유효범위 내에서 상태 값을 보존할 수 있도록 프레임워크에 의해 제어되고 보존되는 key/value 쌍의 collection 이다. 나.ExecutionContext 에 담긴 값들은 jobRepository를 이용해서 프레임워크에 의해 commit 포인트마다 저장된다.ㄱ.JobExecution의 커밋 포인트 : 각 step 이 완료될 때 마다ㄴ.StepExecution의 커밋 포인트 : 각 chunck 단위로 처리될 때 마다..또는 Tasklet 호출단위.
나.ExecutionContext 에 담긴 값들은 jobRepository를 이용해서 프레임워크에 의해 commit 포인트마다 저장된다.ㄱ.JobExecution의 커밋 포인트 : 각 step 이 완료될 때 마다ㄴ.StepExecution의 커밋 포인트 : 각 chunck 단위로 처리될 때 마다..또는 Tasklet 호출단위. 다.Job이 재시작 될 때는, DB에 저장된 executionContext를 읽어와 인스턴스화 하고, Job이 새롭게 시작된 경우에는 빈 객체를 JobExection 또는 stepExecution으로 전달한다.
다.Job이 재시작 될 때는, DB에 저장된 executionContext를 읽어와 인스턴스화 하고, Job이 새롭게 시작된 경우에는 빈 객체를 JobExection 또는 stepExecution으로 전달한다.(database를 사용해서 메타정보를 저장하는 경우라면)
앞의 EndOfDay job 예제에서 DB안으로 파일을 써넣는 작업을 하는 loadData라는 step이 있다고 가정해보라.
첫 번째 실패 이후 meta-data table은 아래와 같다.
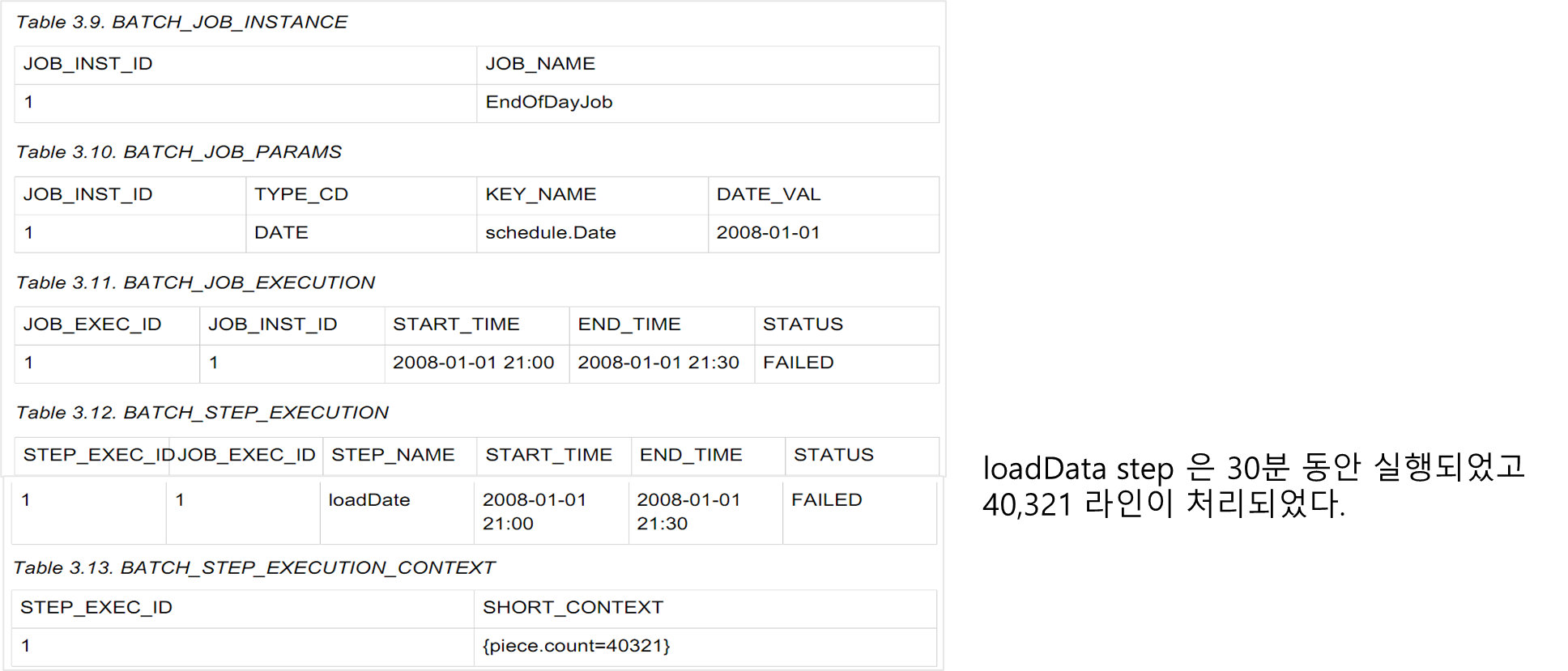
다음날 job이 restart 된다고 가정해보자.
step이 restart 될 때, 지난 실행의 ExecutionContext의 값이 database로 부터 조회되어 재구성되어진다.
ItemReader가 open될 때 ItemReader는 executionContext 안에 어떤 값이 저장되어 있는지 확인 할 수 있고
거기서 부터 스스로를 초기화 할 수있다.

위의 코드가 실행된 후에는 현재 라인은 40322 번째가 될 것이다.
즉, executionContext에 사용자 Data를 넣어둠으로써 이전 Job 실행에서 그만둔 자리에서부터 다시 시작 할 수 있게 코딩 할 수 있다.
(개발자가 어떻게 코딩 하느냐에 따라 restart 시에 어떻게 실행될지 결정된다. 다만, 프레임워크는 좀 거들 뿐…)
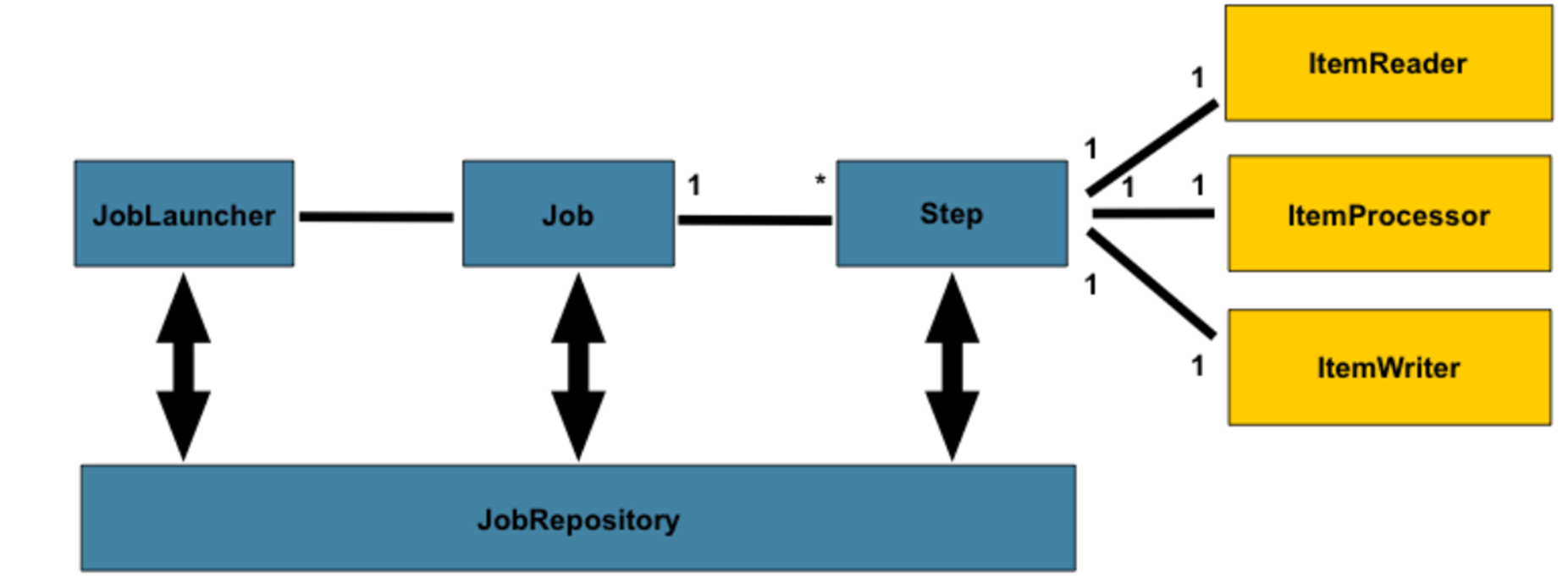
16. JobRepository
•JobRepository는 persistence mechanism 이다. JobLauncher, Job, Step 구현체를 위해 CRUD 기능을 제공한다.•Job 이 처음 시작 되면, repository로 부터 JobExecution이 획득되고•실행이 진행되는 동안 JobExecution과 StepExecution 구현제가 jobRepository에 전달되면서 저장된다.
17. JobLauncher
주어진 JobParameters 를 가지고 Job을 시작 시키기 위한 인터페이스다.
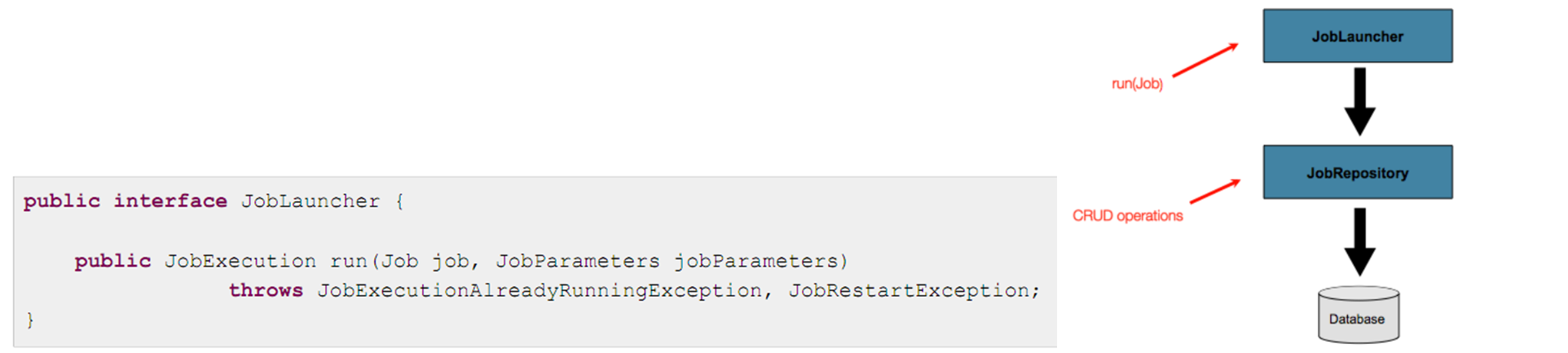
위 JobLauncher 의 코드를 보면, JobRepository로 부터 유효한 JobExecution을 획득될 것이 기대된다.
즉, JobExecution을 생성했다는 것은 Job을 실행 시킨 것을 의미한다.
18. ItemReader
•step에서 한번에 한개의 input item을 조회하는 작업을 추상화한 인터페이스이다.•더이상 조회할 아이템이 없는 경우, ItemReader 는 null을 리턴한다.19. ItemWriter•step에서 한번에 하나의 chunk에 대한 writing 처리를 추상화한 인터페이스이다.*chunk : 하나의 트랜잭션안에서 처리되는 item 덩어리
20. ItemProcessor
•ItemProcessor는 한개의 item에 대한 비지니스 처리를 추상화한 인터페이스이다.•ItemReader가 한개의 item을 조회하고 ItemProcessor가 그 한개의 item에 비지니스 로직을 적용한 결과를 ItemWriter가 chunk단위로 출력작업을 한다.•만약 Item을 처리하는 중에 ItemProcessor가 null을 리턴한다면 item이 유효하지 않아 해당 item은 처리할수 없다는 것을 나타낸다. (즉, write할 item이 없음을 의미한다.)•Chuncked-oriented processing에서 필수사항은 아니다.Chunk-Oriented Processing 에서 ItemReader, ItemWriter는 필수이지만 ItemProcessor는 옵션이다
21. 배치 어플리케이션의 전체 구성(Batch 아키텍쳐 Big Picture)
Batch 아키텍처는 크게 Batch Application의 기동 및 운영관리를 위한 Client, 실제 Batch Job의 수행을 위한 Batch Application Framework, 데이터 및 타 시스템과 연계를 위한 Data/Integration 영역으로 구성되며, 서로간의 연관 관계는 다음과 같이 정의됨
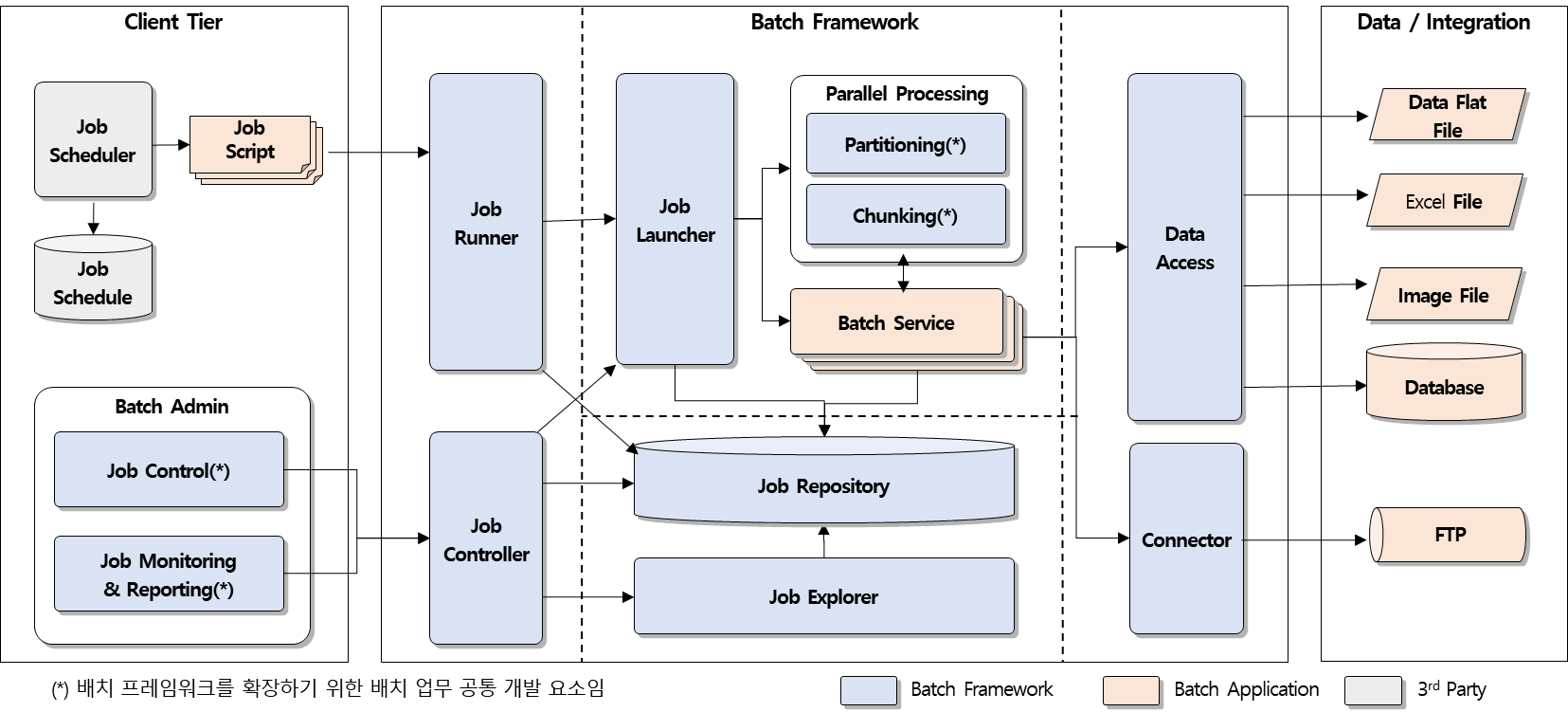

22. Job실행 하기 전 batch meta table 생성하기
(Database 로 배치 실행 이력을 관리하고자 할 경우에만)
1.사용하는 DB 유형에 맞는 테이블 생성 스크립트로 미리 create해 둔다. org/springframework/batch/core/ 아래에 테이블 생성 스크립트 있다.2.jdbc초기화를 이용할수도 있다.<jdbc:initialize-database data-source="dataSource">
<jdbc:script location="org/springframework/batch/core/schema-drop-mysql.sql" />
<jdbc:script location="org/springframework/batch/core/schema-mysql.sql" />
</jdbc:initialize-database>
23. Job 설정하기 – 1) xml namespace 방식(기본 설정)
•Job설정을 위해 다음 3가지가 필수로 요구된다.1.Job이름2.JobRepository3.Step 리스트
24. Job 설정하기 – 1) xml namespace 방식(주요 옵션 설정)
가.재시작가능성 (Restartability)•Job 재시작이란? 어떤 JobInstance의 JobExecution이 이미 존재한다면, 이후의 모든 Job 실행은 restart로 간주된다.•Job의 restartable 속성는 디폴트값이 true로 재시작 가능이다.•restartable을 false로 설정한 뒤 Job을 재시작하면, JobRestartException이 발생한다. (즉, 재시작 되어서는 안될 경우 false로 설정한다.) 나.JobListener
나.JobListenerJob 실행 동안 Job 라이프사이클 이벤트 발생시점에 사용자가 정의한 코드가 실행 될 수 있도록 이벤트 리스너를 추가할 수 있다.
SimpleJob는 적절한 시간에 JobListener를 호출한다.
JobListener로는 JobExecutionListener가 유일하다.
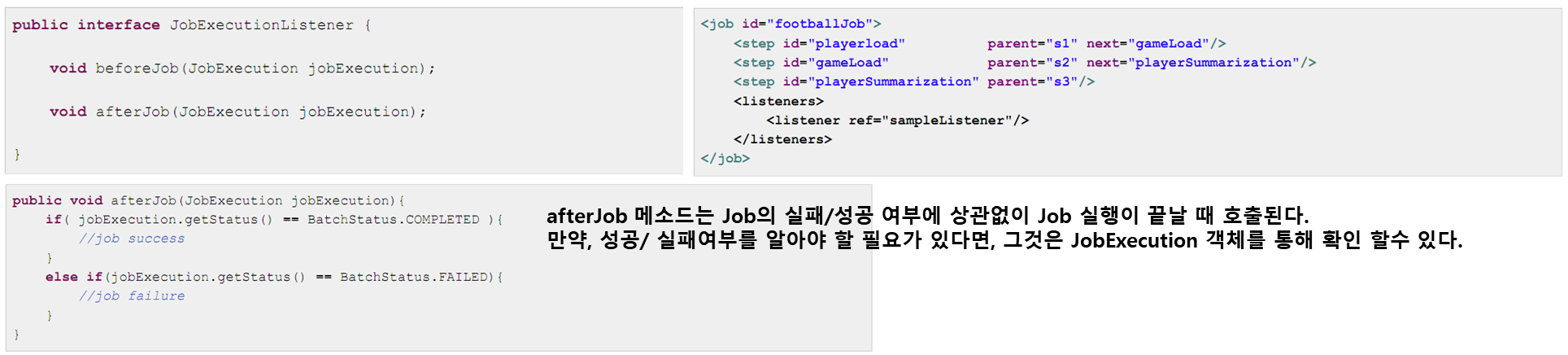 다.부모 Job 상속하기•완전히 동일하지는 않지만 비슷한 설정을 공유하는 Job이 여러 개 있다면 Parent Job을 정의해서 상속을 통해 Job을 정의하면 유용하다.•자바의 상속과 마찬가지로 자식 Job은 자신의 elements와 부모의 elements를 조합한다.•또한 abstract 속성을 true로 하면 부모 Job으로 정의할 때, Job의 필수 요소를 모두 정의하지 않을 수 있다.
다.부모 Job 상속하기•완전히 동일하지는 않지만 비슷한 설정을 공유하는 Job이 여러 개 있다면 Parent Job을 정의해서 상속을 통해 Job을 정의하면 유용하다.•자바의 상속과 마찬가지로 자식 Job은 자신의 elements와 부모의 elements를 조합한다.•또한 abstract 속성을 true로 하면 부모 Job으로 정의할 때, Job의 필수 요소를 모두 정의하지 않을 수 있다. 라.JobParameterValidator
라.JobParameterValidatorJob 런타임 실행시, 입력된 Job 파라미터의 유효성을 체크 하는 validator를 설정할 수 있다.
DefaultJobParameterValidator는 단순히 필수파라미터를 체크하는 JobParameterValidator 의 단순한 구현체이다.
복잡한 유효성 체크가 필요하면, JobParametersValidator 인터페이스를 직접 구현하라.

25. Job 설정하기 – 2) 자바설정(Spring Batch 2.2.0 부터 Spring 3 부터 지원하는 Java config가 지원된다. )
가.@EnableBatchProcessing을 이용하는 방법•dataSource 를 제외한 batch job의 기본 설정을 구성하는 빈들을 제공해준다.•오직 하나의 @Configuration 클래스에만 이 어노테이션을 추가해야한다.•아래는 @EnableBatchProcessing 어노테이션을 config class에 붙이는 것만으로 추가되는 기본 빈 들이다.bean Bean name JobRepository jobRepository JobLauncher jobLauncher JobRegistry jobRegistry PlatformTransactionManager transactionManager JobBuilderFactory jobBuilders stepBuilderFactory stepBuilders 나. BatchConfigurer 인터페이스를 구현하는 방법
@EnableBatchProcessing에서 제공하는 기본 빈 사용하지 않고 직접 설정하고자 할때, BatchConfigurer 인터페이스를 구현한다.

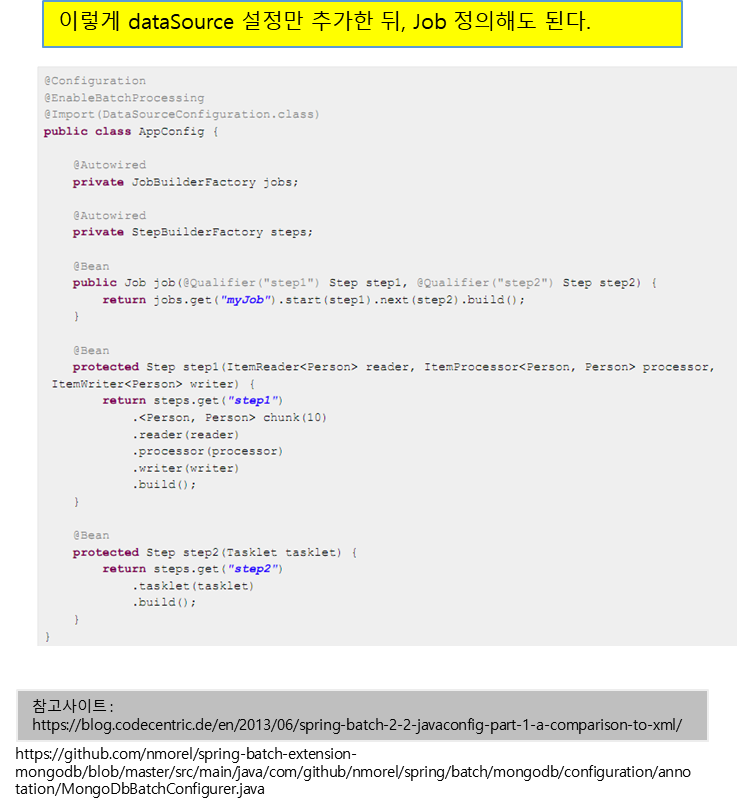



26. JobRepository 설정하기 – 1)
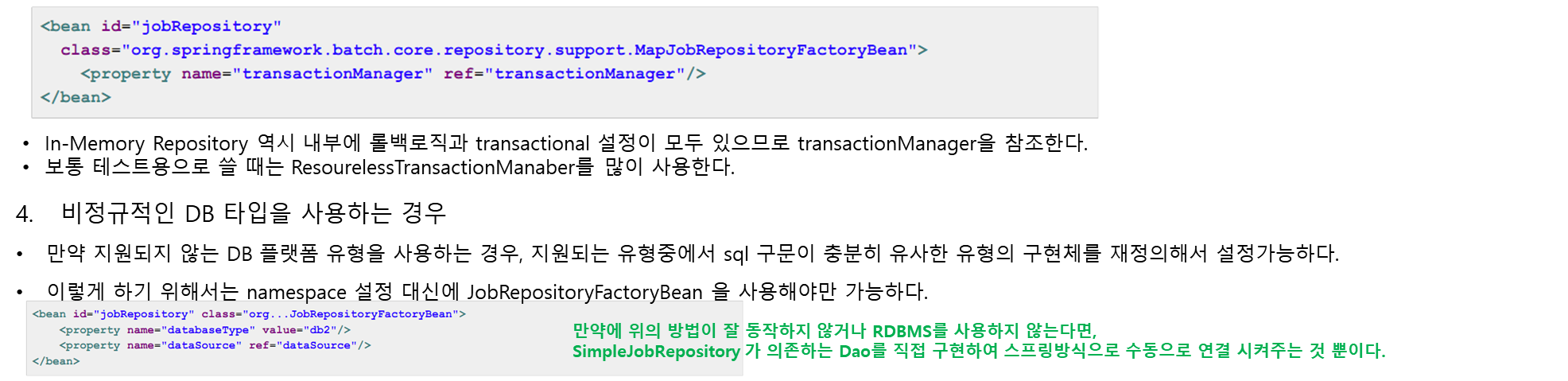
•JobRepository는 JobExecution 이나 StepExecution 같은 meta-data 테이블에 저장되는 배치 도메인 객체에 대한 기본적인 CRUD 기능을 제공한다.•JobRepository 필수설정 항목은 ID 뿐이다. 나머지는 명시적으로 설정하지 않으면 디폴트값이 설정된다. 가.JobRepository를 위한 트랜잭션 설정
가.JobRepository를 위한 트랜잭션 설정Namespace로 설정하거나 JobRepositoryFactoryBean을 통해 설정할 경우, 자동으로 JobRepository 에 대한 트랜잭션 어드바이스가 설정된다.
그렇지 않은 경우, AOP를 사용해서 트랜잭션 어드바이스 설정을 직접 해주는 것이 필수이다. (아마 직접할 일은 없을 것 같다.)
(batch namespace를 사용해서 설정하면 아래와 같은 내용을 포함하고 있다고 생각하면 된다.)

27. JobRepository 설정하기 – 2)



28. JobLauncher 설정하기
•JobLauncher는 JobExecution 객체를 생성하여 Job을 실행하기 위해 JobRepository를 사용한다.•JobLauncher 인터페이스의 가장 기본적인 구현체는 SimpleJobLauncher 이다.•JobLauncher는 JobExecution 획득을 위해 오직 JobRepository 에 대한 dependency 만 필요하다.•일단 JobExecution 이 얻어지면, Job의 실행 메소드를 거쳐 결과적으로 caller(호출자)에게 JobExecution을 반환한다.
29. Job 실행하기
•최소한 Job을 실행하기 위해서는 JobLauncher 와 Job 설정이 필요하다.
command line에서 Job을 시작시킨다면 새로운 JVM이 각각의 Job을 위해 인스턴스화 될 것이므로 모든 Job은 그 자신을 위한 JobLauncher를 가질 것이다.
웹 컨테이너 내에서 실행되는 경우에는 대개 비동기 방식으로 설정되어진 한 개의 JobLauncher 만 가질 것이다.
1) Command Line에서 Job 실행하기
•CommandLineJobRunner 클래스Job을 시작시키는 스크립트는 JVM을 시작시켜야 하기 때문에 실행을 위한 엔트리 포인트로써 main 메소드를 가진 한개의 class가 필요하다. 스프링 배치는 단지 이 목적만을 위해 CommandLineJobRunner를 제공한다.
•CommandLineJobRuuner는 4가지 일을 수행한다.1.명령문의 인자값을 통해 적합한 ApplicationContext를 로드한다.2.명령문의 인자값에서 Job Parameter를 파싱해서 JobParameters 안에 넣는다.3.명령문의 인자값을 통해 알맞은 job을 찾는다.4.Job을 시작시키기 위해 ApplicationContext내에서 제공된 JobLauncher를 사용한다.●•CommandLineJobRuuner 의 필수 argument1번째 인자(JobPath) : job설정파일의 위치로, 이 xml 설정파일에는 job을 실행시키는데 필요한 모든것이 포함되어 있어야 한다.
2번째 인자(jobName) : 실행할 Job 이름
이 두 인자 뒤에 전달되는 나머지 모든 인자들은 JobParameters 로 간주되고 인자의 형식은 name=value 형식이어야 한다.
 •ExitCodes
•ExitCodes- job 프로세스가 스케줄러(호출자)에게 전달하는 실행결과를 나타내는 숫자값 (가장 간단한 경우, 0은 성공 1은 실패이다. )
- JobExecution의 ExitStatus 는 프레임워크 또는 개발자에 의해 설정되는 exit code 속성을 가지고 있다.
- JobLauncher의 반환값인 JobExecution을 받은 CommandLineJobRuuner는 이 속성값(문자)을 ExitCodeMapper 인터페이스를 사용하여 숫자값으로 변환한다.

2) 웹 컨테이너 내에서 Job 실행하기
•리포팅, ad-hoc job, 웹 어플리케이션 지원 등등…HttpRequest로 부터 실행되는 것이 더 나은 경우가 있다.•보통 batch job은 오래 걸리기 때문에 웹 컨테이너에서 실행시킬 때, 가장 중요한 고려 사항은 job을 비동기적으로 실행시키는 것이다.•비동기 방식의 JobLauncher는 즉시 JobExecution을 리턴한다.
30. 메타 데이타 이용 -
1) JobExplorer
•Repository 조회기능을 제공한다. (즉, JobExplorer는 JobRepository의 read-only 버젼이다. )

JobExplorer는 JobRepository와 같은 테이블을 사용하기 때문에 JobRepository 의 table prefix 설정을 변경한 경우 JobExplorer 설정도 동일하게 변경해야한다

2) JobRegistry
•JobRegistry는 생성된 Job을 자동으로 job name과 Job 인스턴스의 Map형태로 관리(추가, 삭제 등)한다.•JobRegistry는 반드시 필요한 것은 아니다. context 안에서 Job을 추적하거나 Application Context 내의 어떤 곳에서 생성되었든 생성되어진 job을 중앙에 모을때 유용하다. •JobRegistry에 Job을 자동으로 등록하는 방법은 두가지가 있다.1.JobRegistryBeanPostProcessor (bean post processor 를 이용하는 방법 ) : Application context가 올라가면서 bean 등록 시, 자동으로 JobRegistry 에 job을 등록시켜준다.
•JobRegistry에 Job을 자동으로 등록하는 방법은 두가지가 있다.1.JobRegistryBeanPostProcessor (bean post processor 를 이용하는 방법 ) : Application context가 올라가면서 bean 등록 시, 자동으로 JobRegistry 에 job을 등록시켜준다. 2.AutomaticJobRegistrar (registry lifecycle 컴포넌트를 이용하는 방법)
2.AutomaticJobRegistrar (registry lifecycle 컴포넌트를 이용하는 방법)이것은 Child Context를 생성하고 그 Child Context에 선언된 job을 등록하는 라이프사이클 컴포넌트이다.
이걸 사용하면 Job Registry에 유니크한 job 이름을 전역적으로 사용할 수 있다.
만약 xml에 선언된 ItemReader의 이름을 reader로 하는 경우, 해당 xml 파일이 다른 많은 xml 설정 파일에 import된다면
reader는 충돌 되거나 다른 것으로 오버라이드 될거라고 예상하지만, AutomaticJobRegistrar 를 사용하면 이를 방지해준다.

3) JobOperator
•job을 stopping, restarting, summarizing 등의 모니터링 작업을 수행
 •Job 중지하기(stopping a job) : 완료되기 전에 JobExecution의 상태가 BatchStatus.STOPPED으로 저장될 것이다.
•Job 중지하기(stopping a job) : 완료되기 전에 JobExecution의 상태가 BatchStatus.STOPPED으로 저장될 것이다.
4) JobParametersIncrementer
ㄱ. 매번 Job을 실행할 때마다 겹치지 않는 JobParameters를 자동으로 만들기 위해 사용하는 것이 JobParametersIncrementer 이다
 ㄴ.JobParameterIncrementer는 인자로 주어진 JobParameter 객체에 대해 필요한 값을 증가시켜 다음 JobParameter 객체를 리턴한다.
ㄴ.JobParameterIncrementer는 인자로 주어진 JobParameter 객체에 대해 필요한 값을 증가시켜 다음 JobParameter 객체를 리턴한다. ㄷ.JobParametersIncrementer는 아래와 같이 job 설정으로 연결된다.
ㄷ.JobParametersIncrementer는 아래와 같이 job 설정으로 연결된다. ㄹ.실행 시 에는, -next 파라미터를 붙여서 실행한다.
ㄹ.실행 시 에는, -next 파라미터를 붙여서 실행한다. •기 실행된 Job executio의 상태가 FAILED 라면 그 JobInsatance는 restart될 수 있으나, ABANDONED상태이면 재시작 될 수 없다.••ABANDONED 상태는 실행 중 특정 step 을 skip하기 위해 마킹용으로 사용된다. 즉, FAILED상태의 job execution을 가진 Job인스턴스를 재시작했을 때 ABANDONED 상태가 마킹된 step을 만난다면, 그 step은 실행되지 않고 다음 step으로 이동하게 될것이다.•v kill -9로 job 프로세스를 죽여버린다면 JobRepository는 해당 job execution에 대한 상태를 저장하지 못하기 때문에 나중에 재시작을 위해서는 Job status를 수동으로 조작해줘야한다.
•기 실행된 Job executio의 상태가 FAILED 라면 그 JobInsatance는 restart될 수 있으나, ABANDONED상태이면 재시작 될 수 없다.••ABANDONED 상태는 실행 중 특정 step 을 skip하기 위해 마킹용으로 사용된다. 즉, FAILED상태의 job execution을 가진 Job인스턴스를 재시작했을 때 ABANDONED 상태가 마킹된 step을 만난다면, 그 step은 실행되지 않고 다음 step으로 이동하게 될것이다.•v kill -9로 job 프로세스를 죽여버린다면 JobRepository는 해당 job execution에 대한 상태를 저장하지 못하기 때문에 나중에 재시작을 위해서는 Job status를 수동으로 조작해줘야한다.
1. Step 이란?
•Step은 Job 내부에 구성되어, 실제 배치작업을 정의하고 제어한다.•즉, Step에서는 입력 자원을 설정하고 어떤 방법으로 어떤 과정을 통해 처리할지 그리고 어떻게 출력 자원을 만들 것인지에 대한 모든 설정을 포함한다.•Step 설정은 2가지 방법이 있다.ㄱ.Chunk-oriented Processing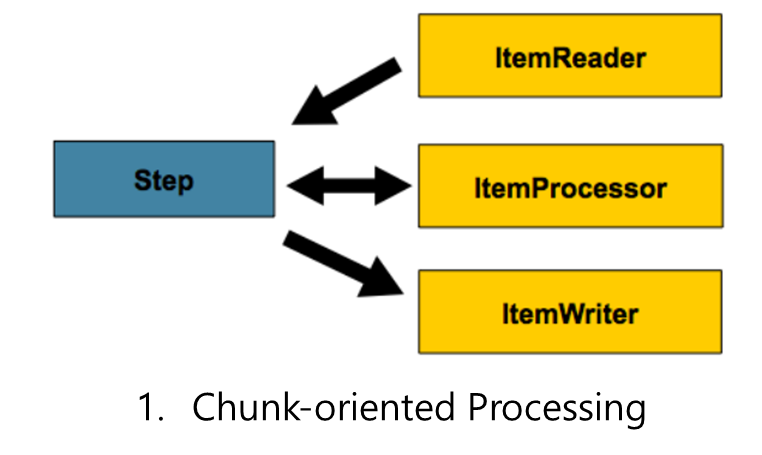 ㄴ.Tasklet Processing
ㄴ.Tasklet Processing •스프링 배치의 가장 일반적인 Step 유형이다.•처리할 Item을 기준으로, Chunk 단위로 read->process->write 를 반복하는 Step 유형이다.가. ItemReader에서 한번에 한 개의 Item을 조회하여,나. ItemProcess에서 한번에 한개의 Item에 비즈니스 프로세스를 적용한 뒤,다. Chunk 단위로 묶인 item들이 한번에 ItemWriter로 전달 되어 쓰이게 된다.
•스프링 배치의 가장 일반적인 Step 유형이다.•처리할 Item을 기준으로, Chunk 단위로 read->process->write 를 반복하는 Step 유형이다.가. ItemReader에서 한번에 한 개의 Item을 조회하여,나. ItemProcess에서 한번에 한개의 Item에 비즈니스 프로세스를 적용한 뒤,다. Chunk 단위로 묶인 item들이 한번에 ItemWriter로 전달 되어 쓰이게 된다.
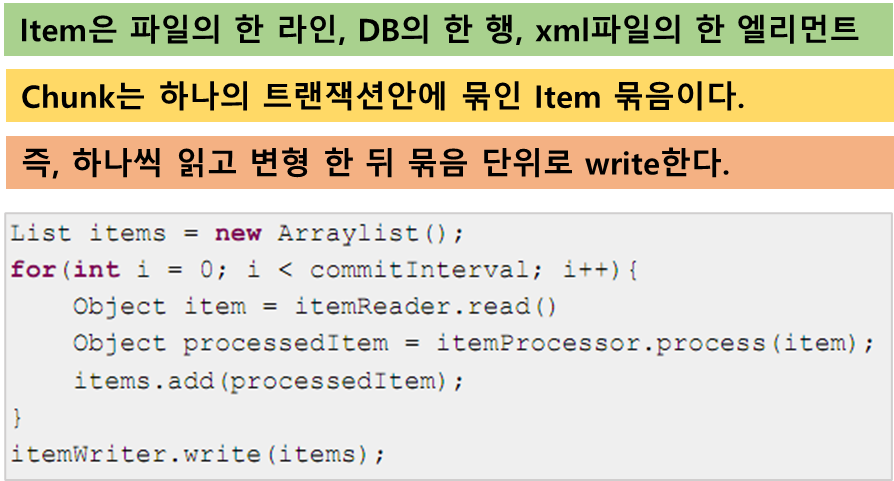
2. Chunk-Oriented Processing
가.기본설정
 • 필수구성요소: ItemReader, ItemWriter, PlatformTransactionManager, JobRepository• 중요속성: commit-interval(하나의 트랜잭션당 처리될 Item 개수), startLimit(step의 실행 제한 횟수)나.상속을 이용한 설정
• 필수구성요소: ItemReader, ItemWriter, PlatformTransactionManager, JobRepository• 중요속성: commit-interval(하나의 트랜잭션당 처리될 Item 개수), startLimit(step의 실행 제한 횟수)나.상속을 이용한 설정 • Job 처럼 Step도 상속된다.• step들이 유사한 설정을 공유한다면, 속성을 상속할 수 있도록 parent step을 설정하는 것이 좋다.•상속 관련 속성
• Job 처럼 Step도 상속된다.• step들이 유사한 설정을 공유한다면, 속성을 상속할 수 있도록 parent step을 설정하는 것이 좋다.•상속 관련 속성parent 부모 step을 지정한다. abstract step 상속을 위해 필수 요소인 reader, writer 가 없는 Abstract Step을 정의 할 수 있다. merge step 내에 있는 <listeners/>같은 list요소는 상속시, child step의 list요소에 의해 기본적으로 오버라이드 된다. 만약 오버라이드가 아닌 병합을 하고 싶은 경우에는 , merge=true를 설정해야한다. 3. Chunk-Oriented Processing – Restart를 위한 step 설정
가.StartLimit•step의 시작 횟수를 제한 한다.• Job 내의 각각의 step에 대해 각각 다른 재시작 설정이 가능하다.(예를 들면, 오직한번 실행되어야 하는 step과 무한히 실행해도 되는 step등등)
• startLimit 을 넘어 실행시키는 경우, exception이 발생한다.• start-limit의 디폴트값은 Integer.MAX_VALUE 이다. 나.Allow-start-if-complete•allow-start-if-complete 속성을 true로 하면, 기존 실행 상태를 오버라이드 하여 항상 step을 실행가능하게 한다.• 즉, 재실행 시에 기존 stepExecution이 성공이든 실패든 상관없이 항상 실행된다.• 항상 실행될 필요가 있는 validation step 이나, 처리 전 resource를 제거하는 작업을 하는 step에 대해 적용할 수 있다.
나.Allow-start-if-complete•allow-start-if-complete 속성을 true로 하면, 기존 실행 상태를 오버라이드 하여 항상 step을 실행가능하게 한다.• 즉, 재실행 시에 기존 stepExecution이 성공이든 실패든 상관없이 항상 실행된다.• 항상 실행될 필요가 있는 validation step 이나, 처리 전 resource를 제거하는 작업을 하는 step에 대해 적용할 수 있다.
4. Chunk-Oriented Processing – Skip logic 설정하기
•Step 처리 동안 예외발생시 Skip처리를 통해 배치의 중단 없이 작업을 실행하기 위함•Skip설정은 Job설정파일의 <chunk> 내부에서 이루어진다. (reader, processor, writer 에서 발생한 예외에 대해서 skip)•Skip된 item의 정보를 확인하기 위해 보통 skipListener를 통해 로깅한다.항목 설명 skip-limit Skip 할 수 있는 최대 횟수를 지정
default=0 이므로 꼭 지정해줘야 Skip기능 이용 할 수 있음<skippable-exception-classes> <include> skip 해야하는 Exception 범위를 지정 <skippable-exception-classes> <exclude> include로 지정한 exception의 하위 exception 중, Skip하지 않을 Exception 지정 
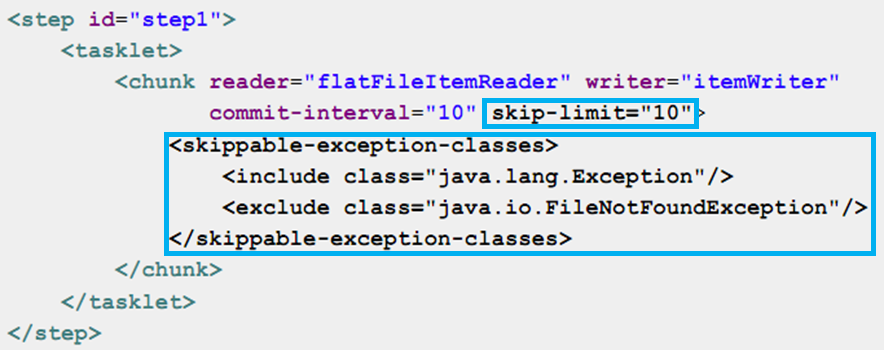 •Skip-limit 설정이 0이 아닌 경우, 반드시 <skippable-exception-classes> 이 존재해야함. 그 반대도 마찬가지이다.•여기서 include , exclude 태그의 순서는 아무상관 없다.•예외 발생시 스킵을 결정하는 것은 class 계층 구조에서 가장 가까운 super class로 결정 된다.
•Skip-limit 설정이 0이 아닌 경우, 반드시 <skippable-exception-classes> 이 존재해야함. 그 반대도 마찬가지이다.•여기서 include , exclude 태그의 순서는 아무상관 없다.•예외 발생시 스킵을 결정하는 것은 class 계층 구조에서 가장 가까운 super class로 결정 된다.5. Chunk-Oriented Processing – retry logic 설정하기
•데이터를 처리하는 Read과정에서 주로 발생하는 FlatFileParseException 에는 대부분 Skip 로직으로 처리가 된다.
반면에, Process 과정과 Write과정에서 발생하는 데이터 선점에 대한 DeadlockLoserDataAccessException 등은 Retry를 통해 해결할 수 있다. 즉, 다른 프로세스에서 처리중인 데이터에 새로운 프로세스가 접근하는 경우 Lock이 걸려 있어 에러가 발생하는데 잠시 후 재시도 하면 성공할 가능성이 있는 것이다.••Retry는 Processor, Writer 하는 동안 예외가 발생했을 경우, 지정한 횟수만큼 데이터 처리를 재시도하는 기능이다.•Skip 과 마찬가지로 Retry를 함으로써, 배치수행의 빈번한 실패를 줄일 수 있게 한다.•Read과정까지 성공한 데이터는 캐쉬에 저장된다. 그러므로 재시도가 일어날 경우 캐쉬의 데이터를 가져와 Process 과정부터 다시 수행한다.•retryable exception은 기본적으로 rollback을 유발하므로 너무 많은 Retry는 성능을 저하시킬 수 있으므로 주의해야 한다.••Retry설정은 Job설정파일의 <chunk> 내부에서 이루어진다.•retry-limit 을 0보다 큰값으로 지정하면 반드시 <retryable-exception-classes>를 지정해야한다.
6. Chunk-Oriented Processing – Rollback 설정
가.롤백 제어하기•Step에 exception 발생시, 롤백을 일으키지 않는 exception 목록을 설정할 수 있다.
나.Tansactional Readers
•ItemReader가 조회하는 자원이 JMS Queue 와 같이 조회에도 롤백 처리가 필요한 자원을 조회할 때 필요한 설정이다.•reader에서 읽어온 item에 대해 버퍼를 사용하지 않도록 설정하는 요소가 is-reader-transactional-queue='true‘ 이다.디폴트는 false 이므로, process나 write에서 처리 하다 retry 되는 경우, 다시 시도 할때 reader를 통해 조회하지 않고 버퍼에 있는 item을 이용 한다

7. Chunk-Oriented Processing – Transaction설정
가.transaction attributestransaction-attributes는 step에 대해 isolation, propagation, timeout 설정을 하기 위해 사용된다

8. TaskletStep
•Step내에서 수행하는 작업이 단순히 프로시저나 스크립트 또는 간단한 sql 구문 호출만으로 구성되는 경우와 같이 Chunk-oriented 처리를 사용하기에 부자연스러운 경우에 사용된다.•TaskletStep을 생성하기 위해, <tasklet/>의 ref 속성에 Tasklet 인터페이스를 구현한 빈을 참조시켜야한다.•<tasklet/> 엘리멘트 내에서 <chunk/> 엘리멘트가 사용되지 않는다.(chunk 태그에서 설정가능한 skip, retry 이용 못함.) •Tasklet 인터페이스는 execute 메소드 하나만 가진다.•execute 메소드는 RepeatStatus.FINISHED 가 리턴되거나, exception이 던져질때까지 TaskletStep에 의해 반복적으로 호출된다.•Tasklet에 대한 각각의 execute 호출 마다 하나의 트랜잭션으로 묶여있다.
•Tasklet 인터페이스는 execute 메소드 하나만 가진다.•execute 메소드는 RepeatStatus.FINISHED 가 리턴되거나, exception이 던져질때까지 TaskletStep에 의해 반복적으로 호출된다.•Tasklet에 대한 각각의 execute 호출 마다 하나의 트랜잭션으로 묶여있다. •Tasklet step은 아래와 같은 작업을 처리할 때 주로 사용한다.1.메인 프로세스가 시작되기 전 리소스들을 설정하는 일을 하는 Step2.처리가 완료된 후에 작업공간의 리소스를 clean up하는 Step
•Tasklet step은 아래와 같은 작업을 처리할 때 주로 사용한다.1.메인 프로세스가 시작되기 전 리소스들을 설정하는 일을 하는 Step2.처리가 완료된 후에 작업공간의 리소스를 clean up하는 Step
9. StepListener
•JobListener와 마찬가지로 Step 라이프 사이클 이벤트에 대해서도 리스너를 추가할 수 있다.•예를 들어, footer를 FLAT FILE에 쓰기 위해 ItemWirter는 Step이 완료되는 시점을 알림 받을 필요 수 있다.•StepListener를 구현한 클래스는 listener element를 통해 적용되고, 이 listener element는 step, tasklet 또는 chunk 내에서 유효하다. •StepListener 인터페이스를 implements한 ItemReader, ItemWriter, ItemProcessor는 네임스페이스의 <step> 엘레멘트에 설정되거나, StepFactoryBean을 사용해서 설정되는 경우 linsteners 엘리멘트에 등록 안해도 자동으로 리스너로써 Step에 등록되어진다. 이렇게 콤포넌트가 직접적으로 Step안으로 주입되어지는 속성인 경우에만 자동으로 등록된다. 그 외의 리스너는 listeners엘리멘트에 직접 등록해주어야 한다.•리스너를 만들기 위해 StepListener 인터페이스 뿐 아니라,어노테이션도도 제공된다. Plain old Java object에 StepListener 에 상응하는 어노테이션을 메소드 레벨에 추가하여 리스너 기능을 구현할 수 있다. ItemReader, ItemWriter, Tasklet과 같은 chunk 컴포넌트의 커스텀 구현체에 어노테이션을 붙이는게 일반적인 방식이다.
•StepListener 인터페이스를 implements한 ItemReader, ItemWriter, ItemProcessor는 네임스페이스의 <step> 엘레멘트에 설정되거나, StepFactoryBean을 사용해서 설정되는 경우 linsteners 엘리멘트에 등록 안해도 자동으로 리스너로써 Step에 등록되어진다. 이렇게 콤포넌트가 직접적으로 Step안으로 주입되어지는 속성인 경우에만 자동으로 등록된다. 그 외의 리스너는 listeners엘리멘트에 직접 등록해주어야 한다.•리스너를 만들기 위해 StepListener 인터페이스 뿐 아니라,어노테이션도도 제공된다. Plain old Java object에 StepListener 에 상응하는 어노테이션을 메소드 레벨에 추가하여 리스너 기능을 구현할 수 있다. ItemReader, ItemWriter, Tasklet과 같은 chunk 컴포넌트의 커스텀 구현체에 어노테이션을 붙이는게 일반적인 방식이다.10. StepListener - 1. StepExecutionListener
•Step 실행과 관련된 이벤트 리스너 이다.ㄱ.Step이 시작되기 전ㄴ.Step이 종료된 후(실패든 아니든 상관없이 ) •Step 완료 시 리턴되는 exit code를 리스너가 변경할 수 있도록 하기 위해, afterStep이 ExitStatus를 리턴한다.•인터페이스에 상응하는 어노테이션은 아래와 같다.ㄱ.@BeforeStepㄴ.@AfterStep
•Step 완료 시 리턴되는 exit code를 리스너가 변경할 수 있도록 하기 위해, afterStep이 ExitStatus를 리턴한다.•인터페이스에 상응하는 어노테이션은 아래와 같다.ㄱ.@BeforeStepㄴ.@AfterStep11. StepListener - 2. ChunkListener
•chunk는 하나의 트랜잭션 안에서 처리되어지는 아이템 집합으로 정의된다.•각 commit interval 마다 트랜잭션을 커밋하는 것은 chunk를 커밋하는 것을 의미한다.•ChunkListener는 chunk 처리 시작전, 또는 chunk가 성공적으로 완료된 후에 어떤 로직을 수행하도록 할때 사용한다. •beforeChunk 메소드는 트랜잭션이 시작해서 ItemReader의 read 메소드가 호출되기전에 호출된다.•반대로, afterChunk 메소드는 rollback이 일어나지 않고 Chunk가 커밋된 후에 호출된다.•인터페이스에 상응하는 어노테이션은 아래와 같다.1.@BeforeChunk2.@AfterChunk3.@AfterChunkError••ChunkListener는 chunk 선언이 하나도 없는 Tasklet Step 에도 적용된다. TaskletStep이 ChunkListener를 호출하는 역할을 수행하기 때문에 chunk-oriented step 뿐아니라 tasklet step 에서도 적용될수 있다. 이때는 tasklet 이 수행되기 전/후에 호출된다.
•beforeChunk 메소드는 트랜잭션이 시작해서 ItemReader의 read 메소드가 호출되기전에 호출된다.•반대로, afterChunk 메소드는 rollback이 일어나지 않고 Chunk가 커밋된 후에 호출된다.•인터페이스에 상응하는 어노테이션은 아래와 같다.1.@BeforeChunk2.@AfterChunk3.@AfterChunkError••ChunkListener는 chunk 선언이 하나도 없는 Tasklet Step 에도 적용된다. TaskletStep이 ChunkListener를 호출하는 역할을 수행하기 때문에 chunk-oriented step 뿐아니라 tasklet step 에서도 적용될수 있다. 이때는 tasklet 이 수행되기 전/후에 호출된다.12. StepListener - 3. ItemReaderListener
•아이템을 읽는 작업에 대한 이벤트 리스너이다. 이전에 SKIP로직을 논의할때, 스킵된 record에 대한 로그를 남기는 것이 이롭다고 언급한 적이 있다.•읽기 중 오류인 경우에는 ItemReaderListener 로 스킵된 레코드에 대한 로깅을 할 수 있다.
beforeRead ItemReader의 read 메소드가 호출되기 전에 호출된다. afterRead ItemReader의 read 메소드 실행이 성공적으로 완료된 후에 호출된다.(즉, item을 성공적으로 읽은 후에 호출) onReadError ItemReader의 read 메소드내에서 읽기 중에 에러가 발생한 경우 호출된다. 발생한 exception을 통해 로깅작업이 가능하다. 상응하는 어노테이션
@BeforeRead
@AfterRead
@OnReadError
13. StepListener - 4. ItemProcessListener
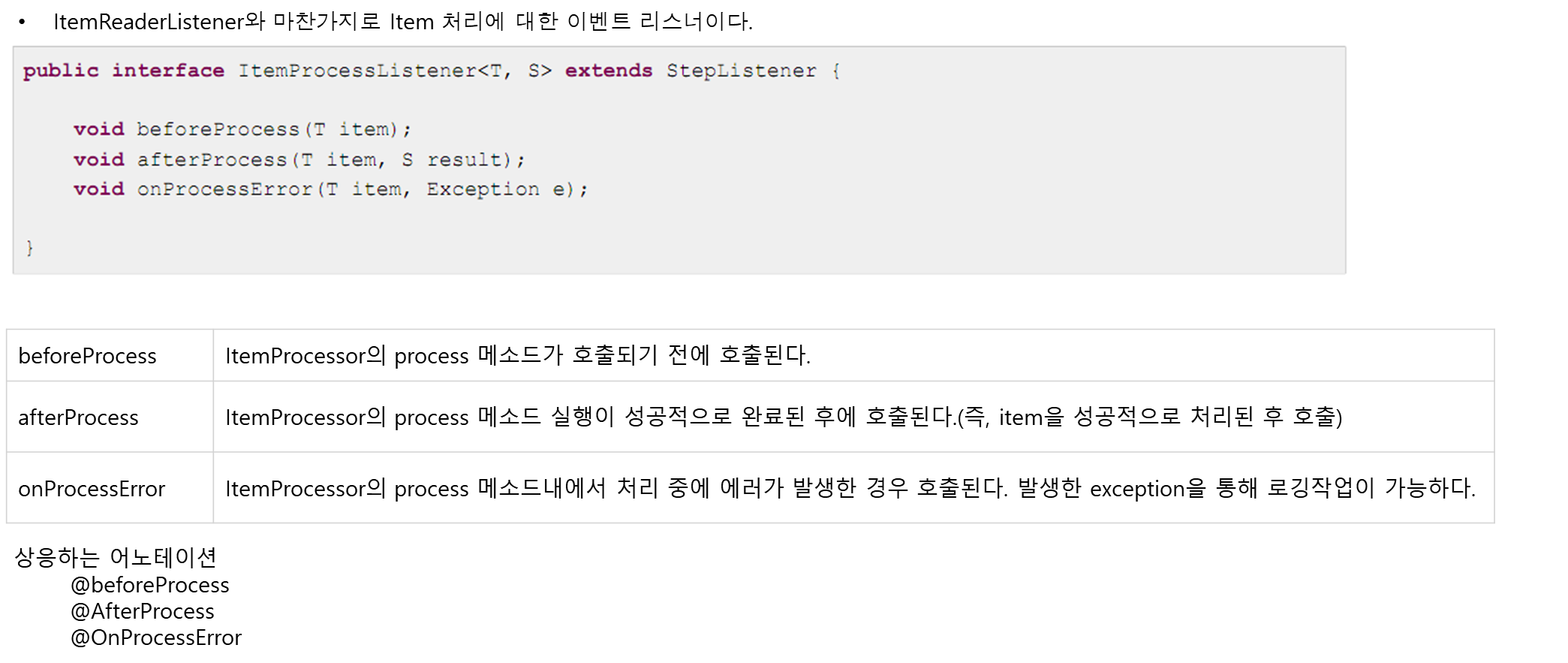
14. StepListener - 6. SkipListener
•ItemReadListener, ItemProcessListener, ItemWriteListener는 모두 에러에 대한 알림을 제공하지만, 실제로 스킵 되어진 record에 대한 정보는 알려주지 않는다.•스킵된 item을 추적하기 위한 SkipListener 인터페이스가 제공된다.
onSkipInRead read 중에 아이템이 스킵될 때마다 호출된다. 같은 아이템이 계속 스킵될 때마다 등록될 수 있기 위해 롤백이 발생할 수 있다. onSkipInProcess process 중에 item이 스킵될 때 호출된다. 이때 아이템은 성공적으로 조회되었으므로 스킵된 아이템이 전달된다. onSkipInWrite write 중에 item이 스킵될 때 호출된다. 이때 아이템은 성공적으로 조회되었으므로 스킵된 아이템이 전달된다. 상응하는 어노테이션
@OnSkipInRead
@OnSkipInProcess
@OnSkipInWrite
SkipListener와 transaction
SkipListener의 가장 일반적인 이용은 스킵된 아이템에 대한 로깅이다. 이렇게 기록된 로그를 이용해 다른 프로세스나 사람이 직접 스킵을 만들어낸 이슈에 대해 수정하거나 계산하는데 이용될 수 있다. 트랜잭션이 롤백 될수 있는 많은 경우가 있기 때문에, 스프링 배치는 2가지를 보장한다.
1. 에러 발생시 적합한 스킵 메소드는 아이템 마다 오직 한번만 호출된다.
2. SkipListener는 트랜잭션이 커밋되기 직전에 호출된다. 그러므로 ItemWrite 내부 실패에 의해 호출된 리스너내의 어떤 트랜잭셔널한 리소스가 롤백되지 않도록 보장한다.
15. Step 흐름 제어하기 - 순차적 흐름
•Job 내에 함께 묶여진 step에 대한 흐름을 제어할 필요가 있다.•어떤Step의 실패가 반드시 Job의 실패를 의미하지 않는다. 게다가 다음에 실행될 Step을 결정하는 성공의 type이 여러 개인 경우도 있다.•Job내의 Step 설정에 따라, 어떤 Step이 전혀 처리되지 않을 수도 있다.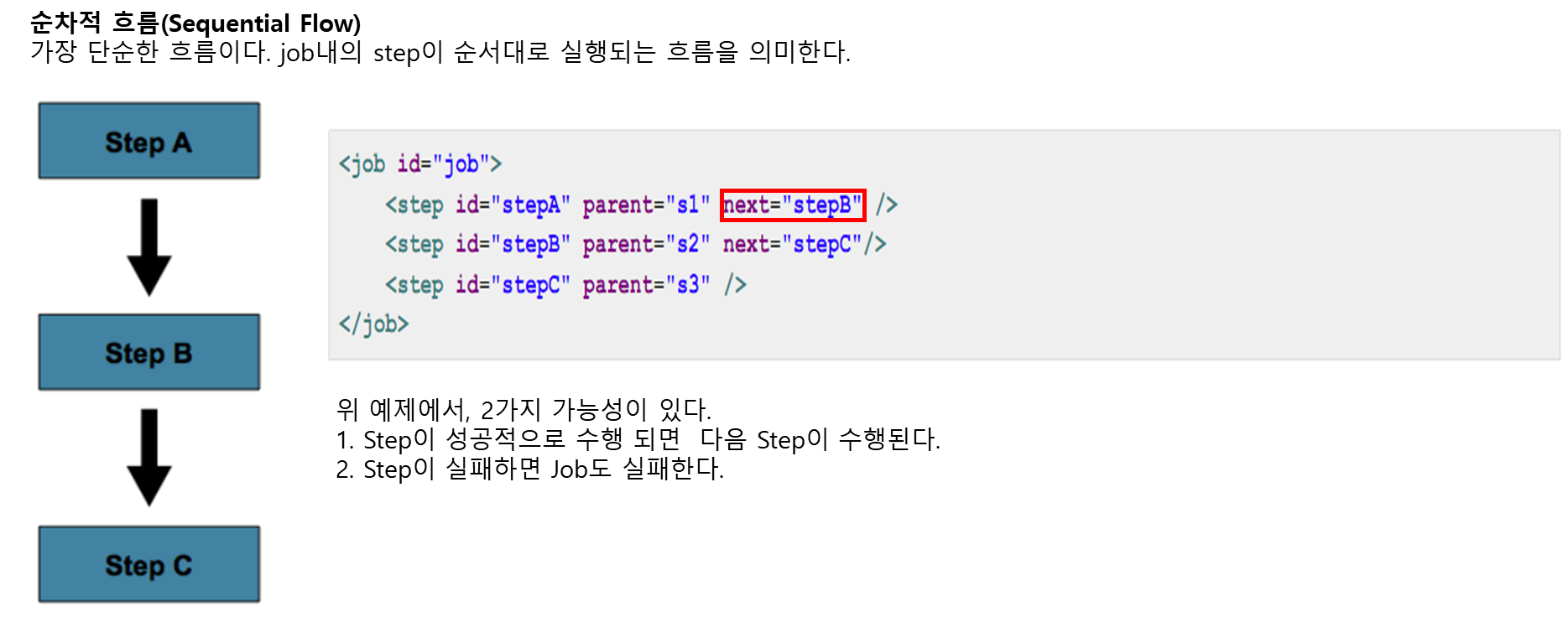
16. Step 흐름 제어하기 - 조건적인 흐름
•조건에 따라 변경되는 흐름으로 Job을 구성하기 위해 step element 내에 transition element를 정의할 수 있다.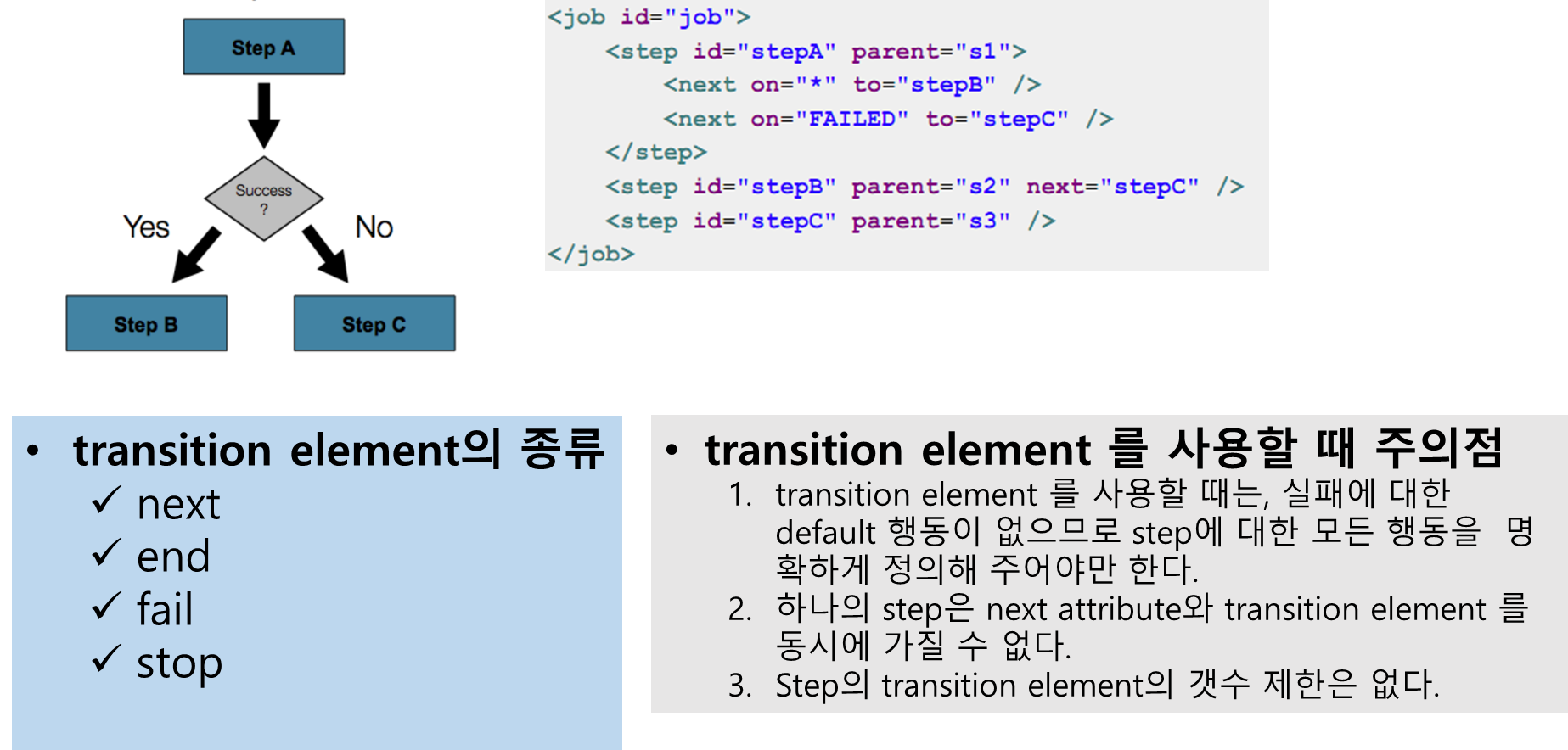
17. transition element - next
•step의 next 어트리뷰트와 마찬가지로 next 엘리멘트는 다음에 실행할 Step을 알려준다.•step의 next 어트리뷰트와는 달리 next 엘리멘트는 하나의 Step에 대해 여러개 설정할 수 있다.
on 속성에는 Step 실행 결과인 ExitStatus의 exitCode에 대한 매칭 패턴을 사용할 수 있다.
사용 가능한 2가지 패턴은 *, ? 이다.
1. * 는 0개 이상 매칭2. + 는 정확히 한개만 매칭on 속성이 참조하는 ExitStatus의 exitCode는 StepExecutionListener의 afterStep으로 변경할 수 있다. 이 메소드가 null이 아닌 ExitStatus를 리턴하면 해당 Step의 ExitStatus는 이 값으로 변경된다. (자세한 내용은 뒤에)
Batch Status Vs. Exit Status
•조건적인 흐름으로 Job을 설정할 때, BatchStatus와 ExitStatus의 차이를 이해하는 것은 아주 중요하다.•BatchStatus1.JobExecution과 StepExecution의 enum 형태의 속성이며, Job 또는 Step의 상태를 기록하기 위해 프레임워크에 의해 사용된다.2.COMPLETED, STARTING, STARTED, STOPPING, STOPPED, FAILED, ABANDONED, UNKNOWN의 값을 가진다.•ExitStatus1.JobExecution과 StepExecution의 속성이며, 실행이 끝난 뒤의 Job 또는 Step의 상태를 나타낸다.2.특히 transition element 인 next element 의 on 속성은 ExitStatus의 exitCode를 참조한다.3.디폴트로, Step의 exit code는 항상 BatchStatus와 같으나 개발자에 의해 변경가능하다.4.exit code를 BatchStatus와 다르게할 필요가 있다면, StepExecutionListener의 afterStep에서 리턴하는 ExitStatus로 변경된다. (null을 리턴하면 BatchStatus와 동일한 디폴트값이 변경되지 않는다.)
18. transition element – stop transition element
•transition element없이 Step이 설정되면, Job의 Status는 아래와 같이 결정된다.•Step이 ExitStatus FAILED로 끝난다면, Job의 BatchStatus와 ExitStatus는 둘다 FAILED 상태가 될것이다.•그렇지 않다면, Job의 BatchStatus와 ExitStatus는 둘다 COMPLETED 일것이다.•결국 Job의 BatchStatus와 ExitStatus는 Step의 ExitStaus에 의해 결정된다.•batch job을 종료하는 방식으로 순차적인 step흐름에 의해 종료되는 Job인 경우가 아닌, 사용자정의로 job을 끝내는 시나리오가 필요할 수도 있다. 이것이 가능 하도록 스프링 배치에서는 Job을 끝내는 3가지 transition element가 제공된다.1.end Element2.fail Element3.stop Element이들 stop transition elemen는 Job내의 Step에 대한 BatchStatus와 ExitStatus에는 전혀 영향을 주지 않는다. 오직 Job의 최종 status에만 영향을 준다.
19. transition element – stop transition element (end)
•Job이 다시는 restart될수 없도록 Job의 BatchStatus를 BatchStatus.COMPLETED 상태로 종료되도록 한다.•Job의 ExitStatus를 수정할 수 있도록 exit-code 옵션도 제공한다. 만약 exit-code 옵션이 설정되지 않는 경우에는, Job의 ExitStatuis의 exit code값으로 디폴트로 "COMPLETED" 가 설정될 것이다. •위의 시나리오에서 만약 step2가 실패한다면, Job은 BatchStatus.COMPLETED, ExitStatus가 "COMPLETED" 코드의 상태로 중지할 것이고 step3은 실행되지 않을 것이다. 만약 step2가 성공했다면, 실행은 step 3으로 이동할 것이다.•여기서 기억할 것은 step2가 실패했을 경우, end element로 인하여 Job의 BatchStatus가 COMPLETED로 설정되기때문에 Job 은 다시는 restart 될 수 없다는 것이다.
•위의 시나리오에서 만약 step2가 실패한다면, Job은 BatchStatus.COMPLETED, ExitStatus가 "COMPLETED" 코드의 상태로 중지할 것이고 step3은 실행되지 않을 것이다. 만약 step2가 성공했다면, 실행은 step 3으로 이동할 것이다.•여기서 기억할 것은 step2가 실패했을 경우, end element로 인하여 Job의 BatchStatus가 COMPLETED로 설정되기때문에 Job 은 다시는 restart 될 수 없다는 것이다.20. transition element – stop transition element (fail)
•fail element는 Job을 BatchStatus.FAILED 상태로 정지시킨다.•end element와 달리, fail element는 Job의 재시작을 막지 않는다. 또한 fail element 역시 Job의 ExitStatus 설정을 위한 exit-code 옵션을 가진다. 이때 eixt-code 디폴트값은 FAILED이다.•아래 시나리오에서, step2가 실패하면, Job의 BatchStatus는 BatchStatus.FAILED 로, ExitStatus는 "EARLY TERMINATION"으로 정지할 것이고, step3은 실행되지 않을 것이다. 그렇지않고 step2가 성공한다면, step3으로 실행이 이동할 것이다. step2가 실패한 후, Job이 restart되면 실행은 step2로 이동할 것이다. 즉, step1은 COMPLETE되었기때문에 restart시에 실행 되지않고 바로 끝난 지점으로 돌아간다.(step2부터 시작된다.)
21. transition element – stop transition element (stop)
•stop element는 Job을 BatchStatus.STOPPED 상태로 중지하게 한다.•job을 stop시키는 것은 Job을 재시작하기전에 break 포인트를 만드는 것이다.•stop element는 restart 어트리뷰트가 필수이며, Job이 재시작될때 실행될 step을 의미한다.•아래예제에서 step1이 COMPLETE로 끝나면, job이 stop할 것이다. 이후에 restart되면 step2부터 시작될 것이다.
Job 하위 element로 step 실행 흐름 제어와 관련된 태그.
1.<split/> : 병행처리기능2.<decision/> : 선언적인 흐름제어 기능3.<flow/> : 흐름의 외재화 기능 728x90반응형
728x90반응형'spring' 카테고리의 다른 글
2. Spring Batch 가이드 - Batch Job 실행해보기 (0) 2023.02.09 1. Spring Batch 가이드 - 배치 어플리케이션이란? (0) 2023.02.09 Spring Boot, 프로젝트 생성하기 (0) 2021.12.02 전자정부프레임워크 버전별 구성 및 서블릿 컨테이너 버전 지원 (0) 2021.05.14 전자정부 표준프레임워크 2016 우수사례 (0) 2021.04.20



