-
(DB공부) OLTP 와 OLAP 차이점, 다차원모델링DB 2021. 5. 10. 12:39728x90반응형
주니어라고 하기에는 너무 나이가 많은 모 책임과 애기하면서
OLTP, DW, 다차원 모델링 애기가 나왔는데, 잘 모른다 했다. 충격... 이것보고 좀 .. 상식을 넓혔으면
OLTP와 OLAP의 차이점
- 효율적인 업무 처리 기반
- 트랜잭션 단위로 처리하기 때문에 소규모의 정교하고 일관된 데이터 처리가 중점(입력, 조회, 수정, 삭제)
- 제한된 Index가 생생되었을 때 최고의 성능을 발휘 (데이터가 변화할 때 Index가 같이 수정되기 때문에 트랜잭션 LOCK에 의해 성능이 저하)
- 운영계로 트렌젝션이 일어나는 과정이 중요 (현재시점)
- 데이터를 저장하는것이 가장 중요하기에 하드디스크 용량, 분산처리, 정규화가 이루어져야함
- 사용하는 목적과 주제에 대한 분석 기반
- 서로 복잡한 이해관계로 얽혀있는 대용량 데이터 처리 및 추출이 중점 (조회, 제한적 입력, 수정)
- 가능한 많은 Index가 존재 할수록 최고의 성능을 발휘(인덱스 수정에 대해서는 고려하지 않음)
- 제한된 Index가 생성되었을 때 최고의 성능을 발휘 (데이터가 변화할때 index가 같이 수정되기 때문에 트랜잭션 LOCK에 의해 성능이 저하)
- 정보계로 운영계의 데이터를 분석하는데 의의를 둠
- 분석의 개념임으로 이력이 가장 중요함 (과거, 현재)
- 데이터를 조회하는것이 가장 중요함으로 메모리 성능, 반정규화의 개념이 중요
- 테이블 자체를 쪼개는 것이 아닌 가장 빠르게 조회할 수 있도록 팩트, 디멘젼 테이블 단위로 구성
오늘은 OLTP와 OLAP환경에 대해 알아보겠습니다.
소위 운영계라는 전통적 데이터베이스 시스템에선 OLAP라는 개념이 필요없다고 생각합니다.
이유는 한개의 트렌젝션이 발생하고 해당 트렌젝션을 insert, update, delete하는 일련의 과정을 하나의 프로세스로 움직이기 때문에
OLAP을 기반으로하는 정보계와는 다른 정보 저장, 운영에 중요성을 두기 때문입니다.
그러나 데이터의 양이 방대해지고 데이터를 통해 insight을 찾으려는 수요가 폭발적으로 증가하면서 정보계 분석의 중요성이 나날이 높아졌습니다. 하여 운영계인 OLTP환경과 정보계인 OLAP환경을 둘다 경험하고 알고 있는 DBA들이 선호되는 추세입니다.
1. OLTP (On-Line Transaction Processing)
여러 과정의 연산이 하나의 트렌잭션으로 실행하는 프로세스입니다.
A라는 사람이 B라는 가게에서 C물건을 구입하는 프로세스라면
1. A사람이 B사람에게 C물건의 값인 1,000원을 지급
2. B사람은 A사람에게 C물건을 제공
3. B사람은 A사람에게 C물건 값인 1,000원 획득
해당의 논리적인 과정이 하나의 프로세스로 이루어져 데이터베이스 내에선 각 테이블에 따라 실행됩니다.
이중 하나의 과정이라도 빠지게 되면 해당 프로세스는 에러가 나고, 모든 단계를 다시 시작해야합니다.
OLTP환경에선 결국 Insert, Update, Delete가 가장 중요하며 현재시점이 중요합니다.
그래서 분산처리의 개념이 나오는 것이 정규화의 중요성이 확대 되는 것입니다. - 처리속도가 빨라야하기 때문에
2. OLAP (On-Line Analytical Processing)
대용량 데이터를 고속으로 처리하며 쉽고 다양한 관점에서 추출, 분석할 수 있도록 지원하는 분석 기술입니다.
OLAP에선 분석이 핵심이 되기 때문에 이력(날짜)이 가장 중요한 속성으로 자리잡습니다 (과거,현재)
또한 Select가 가장 빈번하게 일어나고 그 후 Insert가 일어나기 때문에 메모리 성능이 가장 중요합니다.
그 후 빠른 Select 때문에 정규화가 아닌 반정규화의 개념이 도래하는 것이고, 팩트, 디멘젼 테이블의 개념이 등장하는 이유입니다.
3. 다차원 모델링 (Star, Snowflake Scheme)
I. DW 모델링, 다차원 모델링
DW 모델링 시 사실 테이블과 차원 테이블 간 상호관계를 정의하여 다차원으로 구현하는 모델링 기법
II. 다차원 모델링의 구성요소
구분구성요소
사실
(Facts)중심테이블로서 관련성이 높은 매체 집합
두 가지 Type의 Measure
– Raw(Base) fact / Derived(Calculated) metric차원
(Dimensions)부속 테이블(minor 테이블)
각 Fact를 분석하는 하나의 관점속성
(Attribute)각 차원 테이블이 가지고 있는 속성임
사실을 검색하고, 여과하고 분류할 때 사용됨속성계층
(Hierarchies)차원 내 정의된 속성들 간 존재 계층 관계
아래로 가기(Drill-down)/위로 가기(Roll-up)III. 다차원 모델링 기법
가. Star Scheme 모델링
구성도설명

– 하나의 사실 테이블
– 다수의 차원 테이블
– 적은 Join, 빠른 Query 성능
(+) 쉬운 이해, 계층 정의 용이
(-) 상위레벨 조회 성능 저하나. Snowflake Scheme
구성도설명
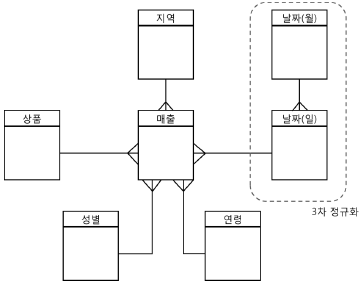
– 차원 테이블을 정규화
– 데이터 중복 문제 해결
– Star Join으로 속도 저하 가능
(+) 데이터 중복 해결, 정규화
(-) Star Join으로 속도 저하IV. 다차원 모델 기법 간 비교
항목Star SchemeSnowflake Scheme
정규화 – 비정규화 – Dimension Table 정규 정합성 – 보장 불가 – 정합성 보장 Join정도 – 적은 Join 성능, 빠름 – Join 횟수 증가, 느림 특징 – 다차원 분석 – 계층화 및 분석 가능 장점 – 조인 수 적임, 고성능 – 소형 테이블, 정규화 단점 – Data 일관성 낮음 – 조인수 많음, 저성능 728x90반응형'DB' 카테고리의 다른 글
(to 김책임) 오라클 insert 속도 향상 팁 (0) 2021.11.05 Oracle Database Linux 계열 백업 쉘스크립트 & 크론탭 (0) 2021.07.06 Linux 서버에서 Oracle dump exp/imp 사용 (0) 2021.07.06 오라클 한글 몇 바이트로 인식되고 있는지 확인하는 방법 (0) 2021.06.29 복합키를 주키(Primary Key)로 사용한 테이블에 외래키(Foreign Key) 참조하는 방법 (재귀 참조) (0) 2021.05.12