단어 토큰화“Hello, World!” -> “Hello”, “,”, “World”, “!”
구두점 분리, 단어 분리
토큰화 실습
# 문장 분리
from nltk.tokenize import sent_tokenize
text = "Hello, world. These are NLP tutorials."
print(sent_tokenize(text))
import nltk from nltk import WordPunctTokenizer
nltk.download('punkt')
text = "Hello, world. These are NLP tutorials."
print(WordPunctTokenizer().tokenize(text))
정제&정규화
불필요한 데이터를 제거하는 작업
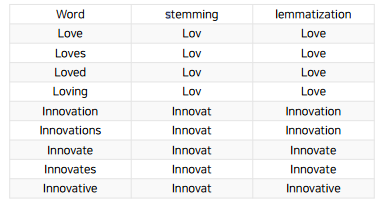
표기가 다른 단어들의 통합 예시) US, USA -> USA, 어간 추출(stemming), 표제어 추출(lemmatization)
대소문자 통합: 문장 첫 글자 문제
불필요한 단어 제거 예시) 불용어(stopwords), 영어가 아닌 외국어
정규표현식
어간추출&표제어 추출
어간추출(stemming)
축약형으로 변환
표제어추출(lemmatization)
품사 정보가 보존된 형태의 기본형으로 변환
어간추출&표제어추출 실습
### 어간 추출 ###
from nltk import WordPunctTokenizer
from nltk.stem import PorterStemmer
from nltk.stem import LancasterStemmer
text = "Hello, world. These are NLP tutorials."
words = WordPunctTokenizer().tokenize(text)
print(words)
porter_stemmer = PorterStemmer()
print([porter_stemmer.stem(w) for w in words])
lancaster_stemmer = LancasterStemmer()
print([lancaster_stemmer.stem(w) for w in words])
#### 표제어 추출 ####
import nltk
from nltk import WordPunctTokenizer
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
text = "Hello, world. These are NLP tutorials."
words = WordPunctTokenizer().tokenize(text)
lemmatizer = WordNetLemmatizer()
print(words)
print([lemmatizer.lemmatize(w) for w in words])
불용어 실습
## 불용어 확인 ##
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
english_stopwords = stopwords.words('english')
print(len(english_stopwords))
print(english_stopwords[:10])
## 불용어 제거 ##
from nltk.corpus import stopwords
from nltk import WordPunctTokenizer
text = "Hello, world. These are NLP tutorials."
stop_words = stopwords.words('english')
stop_words.append('hello')
words = WordPunctTokenizer().tokenize(text)
words = [word.lower() for word in words]
result = []
for word in words:
if word not in stop_words:
result.append(word)
print(words)
print(result)
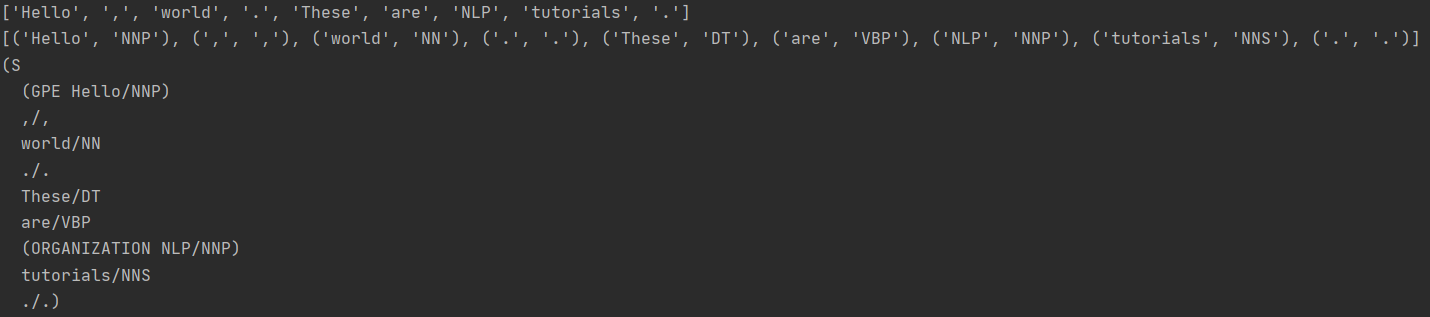
POS Tagging, Named Entity Recognition 실습
# POS tagging (part of speeck tagging)
# Named Entity Recognition
import nltk
from nltk import WordPunctTokenizer
nltk.download('averaged_perceptron_tagger')
nltk.download('words')
nltk.download('maxent_ne_chunker')
text = "Hello, world. These are NLP tutorials."
word = WordPunctTokenizer().tokenize(text)
tagged = nltk.pos_tag(word)
entities = nltk.chunk.ne_chunk(tagged)
print(word)
print(tagged)
print(entities)
토크나이저 실습
import nltk
from nltk.tokenize import sent_tokenize
from nltk import WordPunctTokenizer
from nltk.stem import LancasterStemmer
from nltk.stem import WordNetLemmatizer
types = ['stem', 'lemma', 'pos']
def tokenize(document, type):
words = []
sentences = sent_tokenize(document) # sentence tokenizing
for sentence in sentences:
words.extend(WordPunctTokenizer().tokenize(sentence)) # word tokenizeing
# sentence tokenizing
# word tokenizing
# 타입에 따라서 토큰으로 분리
if type == 'stem':
lancaster_stemmer = LancasterStemmer()
tokenized = ([lancaster_stemmer.stem(w) for w in words]) # stemming
elif type == 'lemma':
lemmatizer = WordNetLemmatizer()
tokenized = ([lemmatizer.lemmatize(w) for w in words]) # lemmatizing
elif type == 'pos':
# tokenized = nltk.pos_tag(words) # pos tagging
tokenized = [token[0]+'/'+token[1] for token in nltk.pos_tag(words)]
else:
raise TypeError
return tokenized
if __name__ == '__main__':
document = '안녕하세요. 이번에 같이 교육받게 된 김지선이라고 합니다.'
print(tokenize(document, 'pos'))






 728x90반응형
728x90반응형