-
그래프 DB로 구축한 시스템 사례업무관련 2023. 2. 20. 15:33728x90반응형
그래프 DB 특징 소개
그래프 데이터베이스는 데이터 수집, 모델링, 분석, 신규 데이터 입력, 연결 관계 처리 영역에서 많은 장점이 있다. 일반적으로 Excel과 같은 집합 데이터를 처리하는 정형화된 업무 시스템과 달리 그래프 DB는 다양한 데이터, 정보 및 지식의 관계를 기반으로 현상(what)에 대한 원인(why)을 추론하고, 미래에 어떠한(how) 의사결정을 할 것인지 예측하기 위한 새로운 업무 영역에서 효과적으로 사용된다.

예시: 그래프 DB 적용 차별성
이를테면, 데이터 기반의 펀드 관리에서 일반적인 표로 펀드를 관리하면 수익률로 나타나는 현상과 수익률에 영향을 미치는 원인의 관계가 명확하게 표현되지 않아 수익률 증대를 위한 데이터 분석 및 의사결정 과정이 복잡해진다. 반면, 그래프 데이터로 관리하는 경우 관계(relationship) 속에서 현상을 직관적으로 바라볼 수 있어 현상에 대한 원인 추론이 가능하고, 향후 의사결정을 위한 데이터 분석 및 예측을 쉽게 할 수 있다. 데이터의 용량이 커지고 연결이 많아질수록 데이터를 활용하여 쉽게 볼 수 있는 방법을 찾게 된다. 데이터를 직관적으로 볼 수 있어야 데이터 분석에 적합하다고 볼 수 있기 때문이다.
대한민국 최고의 싱크탱크가 그래프 DB를 찾게 된 이유
비트나인의 그래프 DB인 AgensGraph는 한국개발연구원(KDI)이 수행하는 경제발전경험 공유사업 프로젝트 정보를 관리한 사례가 있다. KDI는 1971년 설립된 대한민국 최초의 사회과학분야 종합정책 연구소로서 국내 연구기관 중 첫 손에 꼽히는 대한민국 최고의 싱크탱크이다. KDI 국제개발협력센터(CID)는 2004년부터 해외 협력국을 대상으로 우리나라의 경제발전경험 공유사업을 수행해오며 축적한 다양한 정보 간의 연계성을 직관적으로 확인할 수 있는 지식 관리 체계를 구축하고자 하였다. 이를 위해 새롭게 적용되고 있는 기술들의 현황을 살펴보고 신규 개발 협력 사업의 기획・발굴에 이를 어떻게 적용할 수 있을지 검토하던 중, 데이터 연결 관계 처리와 데이터 분석 영역에서 강점을 가진 그래프 DB를 선택하였다.
경제발전경험 공유사업은 사업 발굴에서 성과 관리에 이르는 일련의 life cycle에 따라 체계적으로 진행되고 있었으나, 그래프 DB를 적용하기 전까지 개발협력 사업에 대한 정보는 파편화된 엑셀 테이블 단위로 관리되고 있었다. 각 테이블 데이터 간 연계성이 부족하여 다양한 요소 간의 관계 파악 및 사업 분야별, 단계별 매칭이 어려웠고, 참여 기관, 전문가 등 사업정보 변경에 따른 테이블 및 애플리케이션 유지와 관리에 큰 비용과 많은 시간이 소모됐었다. 또한, 기존의 테이블 간 연계를 시도할 때 데이터의 관계(path)가 깊을수록 수 없이 반복되는 join 연산에 의한 성능 문제가 발생해서 개발 협력 데이터를 효과적으로 활용하는 데 필요한 심층 질의에 한계가 있었다.
테이블 join 연산을 보여주는 예시
본 사례는 개발협력사업 지식체계 구축에 적용 가능성을 검증하기 위해 프로젝트 정보를 그래프 모델링을 통하여 구조화하고 DB에 적재했다. 그래프 DB를 통해 직관적이고 숨겨진 가치를 탐색할 수 있게 되었으며, 데이터 추가, 변경 및 삭제 등에 대한 관리가 유연하다는 통찰을 얻을 수 있었다.
그래프 기술을 도입한 목적은 데이터를 효과적으로 연계, 관리 및 활용하기 위한 방안을 검토하기 위함이었고, 이에 따라 그래프 기술은 효과적인 정보 검색, 맞춤형 추천시스템 등 업무 효율성 제고를 위한 지식포털을 구축하여 그래프 기술 활용의 타당성을 검증했다.
그래프 기술이란 그래프 DB를 기반으로 한 기술들로 지식 그래프, 그래프 분석, 그래프 시각화 등을 포함한 하나의 집합체이다. 그래프 기술의 가장 큰 핵심 중 하나인 직관성은 데이터를 이해하고 분석하는 데 도움을 준다. 그래프 기술의 어떤 점들이 직관적인지는 아래와 같이 알 수 있다.
직관적인 솔루션, 그래프 DB를 적용하다
1) 직관적인 그래프 시각화
첫째는 그래프 시각화다. 그래프를 통해서 육안으로 확인하기 힘들었던 숨겨진 패턴을 쉽게 파악할 수 있다. 데이터 관계 시각화는 데이터의 질의 후 테이블 모델보다 그래프 모델의 표출 방식이 더 우수한 직관성을 가지고 있다.
직관적인 그래프 데이터 시각화
그래프 DB는 정형화된 스키마(schema)가 없다는 특성을 가지고 있기 때문에 노드, 엣지, 속성 등을 유연하게 추가할 수 있다. 특정 시점에서 분석의 깊이를 이해하기 위해 속성을 추가하는 작업이 들어갈 때 사용하기 적합하다.
2) 직관적이고 간단한 그래프 질의 언어
그래프 질의는 직관적이고 변해가는 데이터에 최대한 유지보수를 줄일 수 있다. 대표적인 예시로 많은 그래프 DB 벤더들이 채택한 표준 언어인 OpenCypher가 그러하다. 기존 질의문인 SQL은 발생 가능한 case를 모두 알아야 원하는 질의가 가능하다. 복잡한 데다 사용자의 실수 유발 시, 유지보수에 어려움이 발생할 수 있다.
아래의 예시를 통해 SQL과 Cypher에 질의어를 비교해보자.
예시) “특정 카테고리의 사업 또는 세부 주제에 대한 수행 경험은 있으나, 관련 업체 혹은 사업과 이해관계(용역, 연구, 재직, 타당성 조사 등)가 없는 인물을 검색”
SQL:

SQL은 구조적 질의 언어의 줄임말로 관계형 DB에서 자료를 관리 및 처리할 때 사용되는 언어다. 현재 SQL의 표준으로 ANSI SQL이 정립되었다. 기존 SQL은 조건문, case, union, join 등을 모두 알아야 원하는 질의가 가능하다. 복잡하기 때문에 사용자 실수 유발 시 유지보수에 어려움이 발생할 수 있다.
Cypher:

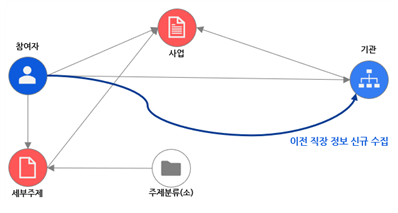
Cypher는 프로퍼티 그래프의 효율적인 질의 및 업데이트를 허용하는 그래프 질의어이다. “MATCH (P:참여자)-[]-(o:기관) return” 등의 패턴 질의문은 일부 중간 관계를 모르거나 삭제되어도 쉽게 찾을 수 있고, 질의어가 변경되지 않는다. 그래프 DB의 질의문이 간단한 만큼 찾고자 하는 것만 알면 데이터 조회가 쉬워진다.
아래 KDI에서 그래프 DB 시나리오 기반 데모를 통해 조회했던 질의문을 설명하고 결과를 그래프 모델로 나타냈습니다. 시나리오에서 언급되는 전문가의 이름들은 개인정보를 보호하기 위해 blur 처리를 했습니다.
시나리오 1 - 특정 전문가의 참여 이력과 관련 정보 조회
질의문
match p1=(v1:person)-[]-(v2:subject)-[]-(v3:category_3)
, p2=(v1)-[]-(v4:project)-[]-(v5:country)
, p3=(v2)-[]-(v4)
, p4=(v1)-[]-(v6:project)-[]-(v7:country)
where v1.name = 'OOO_한국개발연구원'
return *
설명
기존에는 전문가의 정보를 찾아보려면 수많은 문서들을 조회하는 불편함이 있었지만, 모든 데이터의 관계를 연결하는 그래프 DB 덕분에 정보 조회가 간편해졌다. 특정 전문가의 기존 사업의 참여 정보를 조회하기 위해 전문가 중심의 검색을 실행한 결과, 전문가가 기존에 참여하였던 사업과 그 사업이 어느 국가에서 수행되었는지 등의 정보를 한눈에 볼 수 있고, 주로 참여해왔던 사업들의 공통 주제 등을 파악하여 그 전문가의 전문분야를 확인한다.
결과
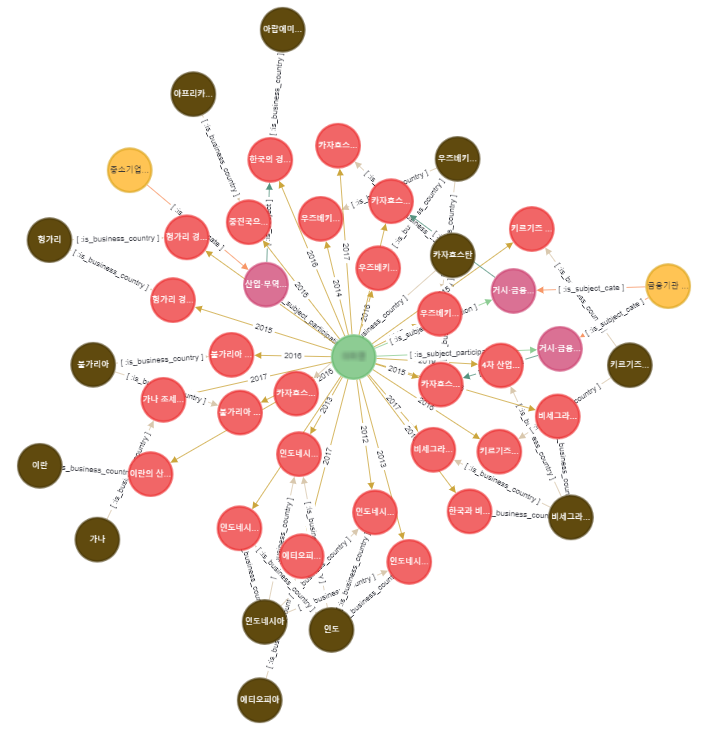
특정 전문가의 참여 이력과 관련 정보 조회
특정 전문가는 총 26개의 사업에 참여했고, 관련 국가는 13개국이고, 사업의 세부 주제는 산업 무역, 거시금융 등으로 확인된다.
시나리오 2 - 특정 국가에서 특정 주제(예: 산업무역 정책)에 관한 사업을 수행한 전문가 확인
질의문
match p1=(v1:person)-[r1]->(v2:project) ,p2=(v2)<-[r3]-(v3:subject)
where v3.'지역'='아시아' and v3.국가='캄보디아' and v3.'주제분류(중)'='산업·무역 정책'
return *
설명
캄보디아에서 진행했던 ‘산업무역 정책’ 사업을 조회하고, 이를 기준으로 사업을 수행한 전문가들을 파악한다. 총 몇 명의 전문가들이 참여했는지와 그 많은 사업 중에 가장 많이 연관된 전문가를 확인한다.
결과
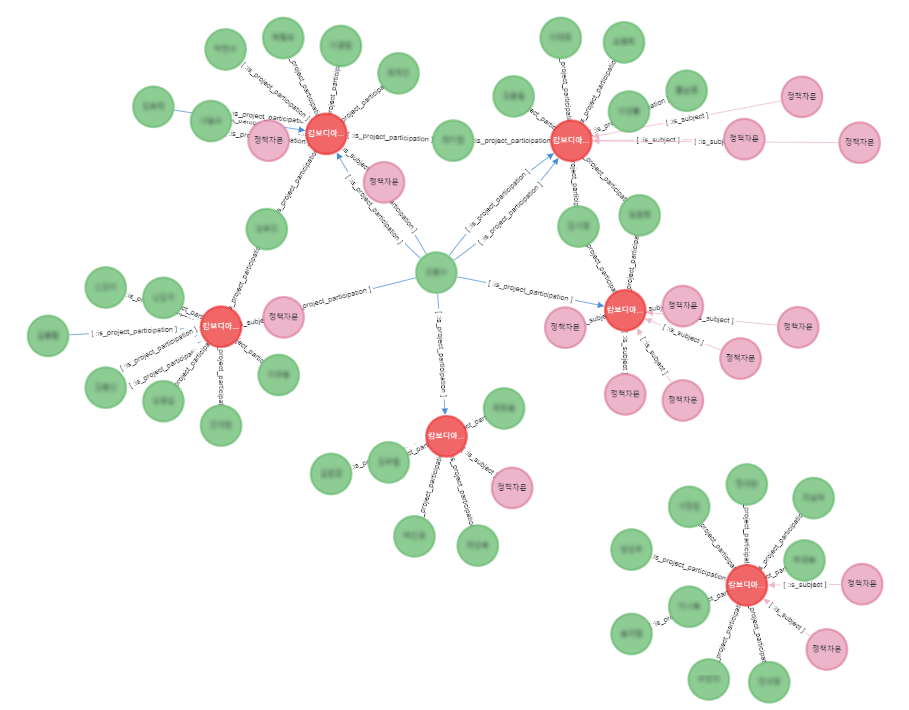
특정 국가에서 ‘산업무역 정책’을 사업을 수행한 전문가 확인
아시아 지역의 캄보디아에서 ‘산업무역 정책’ 사업은 총 6건이 진행되었으며, 해당 사업을 수행한 전문가는 총 37명이다. 그중 특정 전문가는 6건의 사업 중 5건의 사업을 수행했다.
그래프 분석 기술력의 적합성
그래프 분석은 기존 테이블 형태의 데이터 집합에 대한 분석이 아닌, 노드와 엣지 형태로 구성된 그래프 데이터를 분석하는 행위를 의미한다. 이러한 데이터 분석 기술을 기반으로 통합 데이터의 분석에 적용 시, 기존 통계 분석으로는 판단할 수 없었던 새로운 관점의 분석 서비스에 접근할 수 있다. 이를테면, 복잡한 머신러닝 기술을 적용하지 않아도 군집화 및 중심성 등의 그래프 알고리즘을 구현하여 데이터 분석을 실현할 수 있다.
특정 사업이나 특정 분야의 전문가를 파악하기 위해서 인물 정보가 자주 활용된다. 그만큼 인물 정보는 개발협력사업에서 중요한 정보 중 하나이다. 그래프 DB는 중심성 분석을 통해 영향력이 높은 사람들의 네트워크에 얼마나 많은 관계가 이루어져 있는지를 보는 지표를 산출할 수 있다. 이러한 그래프 알고리즘 분석 기법을 통해 관계형 DB에서는 알 수 없었던 중간 매개로써 중요한 역할을 수행하는 인원들을 알 수 있었고, 전문가들과 업무를 수행하고 있는 인원들을 모두 파악할 수 있었다.
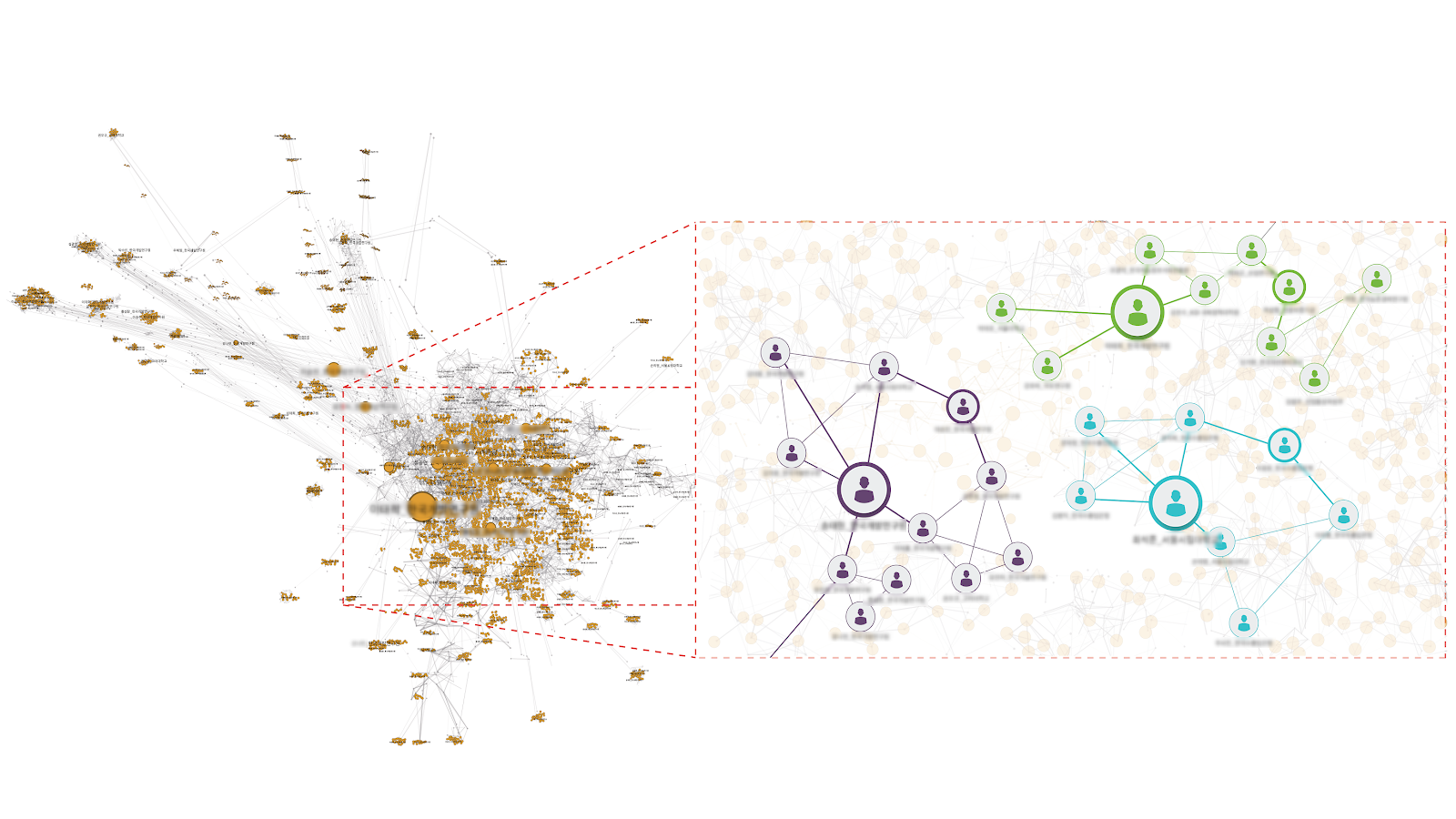
전문가 네트워크 (출처: 개발협력 지식관리 체계화 연구 최종보고서, KDI)
중심성 분석(Centrality Analysis)이란?
네트워크에서 중심성(centrality)을 통해 가장 영향력이 큰 전문가를 파악하여 사업 추천 또는 성과 관리에 활용할 수 있다. 본 사례의 경우, betweenness centrality를 통해 기존 테이블로는 보기가 쉽지 않았던 중계자로서 중요한 역할을 수행하는 인원들을 알 수 있고, page-rank centrality로 중요 연구자들과 업무를 수행하고 있는 인원들이 누구인지 발견할 수 있었다.
공동체 탐색(Community Detection)이란?

전체 네트워크의 군집 결과
전체 네트워크에서 연관성이 높은 노드들을 같은 집단(community)으로 묶는 그래프 군집(clustering) 알고리즘이다. 기존에는 전문가들의 정보가 기존 참여 주제나 소속 기관으로 분류되는 경우가 많았다. 하지만 전문가의 지식은 범위가 넓고 확대될 수 있기 때문에 전문분야가 바뀔 때도 있다. 전문가의 관심이나 연구 분야가 바뀌는 경우 특정 분야에만 한정해서 관리하기에는 무리가 있다. 그래프 DB를 활용할 경우, 전문가의 전문 분야 정보 이외에 이들이 참여했던 사업이나 연구의 다른 공동 참여자 또는 전문가 정보를 파악하여 군집 분석에 활용한 통합적 분석이 가능했다.
결론
그래프 DB는 연관관계 분석에 특화된 데이터베이스로 알려져 있다. 기존 데이터베이스로는 이메일, PDF 문서, 이미지, 영상 등 다양한 형태의 데이터 관리 및 분석에 어려움이 있어 그래프 기술로 극복한 것이다. 한국개발연구원(KDI)의 국제개발협력센터(CID)는 개발협력 사업의 지식관리를 하는 데 있어 그래프 알고리즘과 시각화를 통해 효과적인 인력 매칭 시스템을 구축할 수 있었다.
그래프 시각화 분석은 특성상 대량의 빅 그래프를 조회할 수도 있고, 그래프의 특정 부분만 집중해서 볼 수도 있다. 즉, 거시적인 시각화와 미시적인 시각화가 필요하며 두 양극단을 사용자 인터페이스가 제공한다면 더 효과적인 분석 플랫폼을 구현하여 업무 흐름에 유의미한 통찰을 얻을 수 있을 것이다.
참고문헌
홍성창, “개발협력 지식관리 체계화 연구: 데이터 현황과 활용 방안을 중심으로”, KDI 국제개발협력센터, 12/30/2021, 179-223쪽
https://www.kdi.re.kr/research/subjects_view.jsp?pub_no=17458
728x90반응형'업무관련' 카테고리의 다른 글
지식그래프의 시맨틱웹언어 중 하나, RDF (Resource Description Framework) 의 개념 (0) 2023.02.20 지식그래프와 지식그래프DB 개념 (0) 2023.02.20 지식그래프(온톨로지) 개념과 설계 (0) 2023.02.20 티카 소스 (0) 2022.06.27 브레이브 브라우저 (0) 2022.01.26
