왜 GPU와 CUDA가 인공지능 프로그래밍에 필요하나?
GPU와 CUDA는 인공지능 개발에서 사용되는 이유는 크게 두 가지로 나눌 수 있습니다.
첫째, 딥러닝 모델은 대규모의 데이터와 복잡한 계산이 필요하기 때문에, 고성능 컴퓨팅 자원이 필요합니다.
따라서 GPU는 CPU에 비해 많은 수의 코어를 가지고 있고, 병렬 처리를 위해 설계되어 있어 대규모 데이터의 병렬 처리와 계산에 효과적입니다. 이에 따라, 딥러닝 모델 학습에 사용되는 대용량 데이터의 처리 속도를 높이는데 유용합니다.
둘째, CUDA는 GPU에서 병렬 처리를 위해 사용되는 프로그래밍 언어입니다. CUDA는 GPU에서 동작하는 커널 함수를 작성할 수 있도록 지원하며, 이를 통해 빠른 연산이 가능해집니다. 또한 CUDA는 CPU와 GPU 사이의 데이터 전송을 최소화하여 성능을 향상시키는데 기여합니다.
따라서, GPU와 CUDA는 인공지능 개발에서 대규모 데이터 처리와 빠른 계산을 위해 필수적인 요소입니다.
- CUDA Toolkit Documentation
- Programming Massively Parallel Processors
Contents
- CPU와 GPU차이
- GPGPU VS CUDA 도입
- 간략한 GPU Architecture
CPU와 GPU 차이
수년 동안, Intel Pentium이나 AMD Opteron 프로세서와 같은 단일 CPU를 이용한 마이크로프로세서의 성능은 빠르게 향상되었고, 컴퓨터 어플리케이션의 비용은 감소되었습니다.
요즘 데스크탑에 사용되는 마이크로프로세서는 수 GFLOPS(Giga(109) Floating-Point Operation per Second)의 성능을 보이고, Datacenter에서 사용되는 마이크로프로세서는 수 TFLOPS(Tera(1012) FLOPS)의 성능을 보여주고 있습니다.
하지만 이런 성능의 향상은 2003년 이후로는 둔화되기 시작했는데, 에너지 소모나 발열 이슈로 인하여 클럭 주파수와 한 클럭에서 수행할 수 있는 수행 능력을 증가시키는데 한계가 생겼기 때문입니다. 이후로, 거의 모든 CPU 제조사들은 하나의 칩에 여러 개의 (프로세서 코어라 불리는)프로세서 유닛을 집적하여 연산 능력을 증가시키는 방향으로 전환했습니다. 이러한 전환은 소프트웨어 개발에 큰 영향을 미치고 있습니다.
2003년 이후로 반도체 업계에서는 마이크로프로세서를 두 가지 전략을 가지고 설계하였습니다.
하나는 multicore 인데, 이 전략을 사용하면서 순차 프로그램(Sequential Program)의 실행 속도 향상을 추구합니다.
멀티코어는 2-core 프로세서부터 시작하여 반도체 공정 세대마다 코어의 수가 증가하고 있습니다. 최근에 Intel의 i9 프로세서의 경우에는 16개의 core를 가지고 있고, 각 코어는 2개의 하드웨어 스레드를 가지고 하이퍼스레딩(hyper-threading)을 지원하여 순차 프로그램의 실행 속도를 최대화하도록 설계되었습니다.
반대로 many-thread(many-core) 전략은 병렬 프로그램의 처리량에 더 초점을 맞춥니다.
many-thread는 대량의 스레드를 사용하며, 세대마다 스레드의 수는 증가하고 있습니다.
Many-thread 프로세서, 특히 GPU는 2003년 이후부터 부동소수점(floating-point) 연산 성능을 주도하고 있고, 2016년 기준, GPU의 부동소수점 연산 처리량이 멀티코어 CPU의 약 10배정도 높습니다.
(이 비율은 실제 어플리케이션을 실행하여 얻을 수 있는 비율을 의미하는 것은 아니고, 프로세서로부터 얻을 수 있는 최대 연산 속도의 비율입니다.)
요즘에는 이 성능 차이가 더욱 크기 때문에 개발자들은 소프트웨어에서 계산량이 많은 부분을 GPU에서 수행하도록 변경하고 있습니다.
many-core GPU와 범용 multicore CPU 사이의 성능 차이는 프로세서 설계 철학이 근본적으로 다르기 때문입니다.
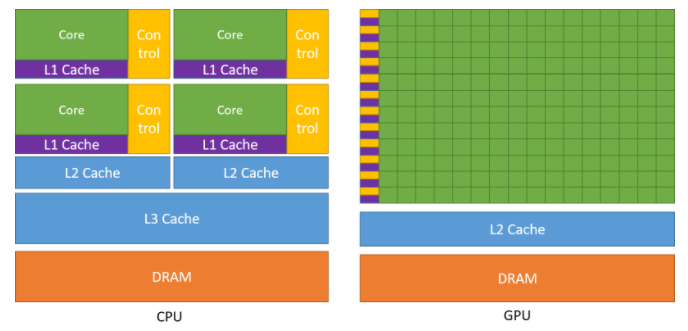
방금 위에서도 언급했지만, CPU는 순차적인 코드(sequential code)의 성능을 최적화하도록 설계되었습니다.
조금 더 자세히 설명하자면.., 겉으로 보기에는 순차적으로 실행하지만, 실제로는 단일 스레드를 구성하는 명령어들은 병렬적으로, 또는 비순차적으로 실행하는 복잡한 제어 로직을 사용합니다.
중요한 것은 어플리케이션에서 명령어와 데이터 접근 지연시간을 줄이기 위해서 큰 캐시 메모리를 사용합니다만, 복잡한 제어 로직이나 이런 캐시 메모리는 연산 속도에는 영향을 끼치지 못합니다.
위 이미지에서 CPU에는 커다란 코어 4개와 여러 종료의 캐시 메모리를 넣은 모습입니다.
메모리 대역폭(bandwidth)도 중요한 이슈인데, 많은 어플리케이션의 속도는 메모리 시스템에서 프로세서로 전달해야하는 메모리의 비율에 따라서 제한됩니다.
그래픽(Graphcis) 칩은 현재 사용가능한 CPU 칩보다 약 10배의 대역폭을 가지고 동작합니다.
GPU는 graphics frame buffer 요구사항 때문에 매우 많은 양의 데이터를 DRAM의 내외부로 이동할 수 있습니다.
반면에 범용 프로세서(CPU)는 legacy OS, 어플리케이션, I/O 디바이스들의 요구사항을 만족해야하기 떄문에 메모리 대역폭을 늘리는 것이 어렵습니다.
따라서, GPU의 경우에는 더 간단한 메모리 모델을 사용할 수 있고 legacy 소프트웨어에 대한 제약 사항이 거의 없어서 상대적으로 쉽게 메모리 대역폭을 높일 수 있는 이점이 있습니다.
GPU의 설계 철학은 빠르게 성장했던 비디오 게임 산업에 의해서 형성되었는데, 당시에는 고급 게임들에서 비디오 프레임당 엄청난 수의 부동소수점 연산을 수행할 수 있어야 경쟁에서 이길 수 있는 산업 전반의 압박이 있었습니다.
이 때문에 GPU 업체들을 칩의 면적과 전력을 부동소수점 연산에 최대로 할당하기 위한 여러 방법들을 찾기 시작했고, 결과적으로 지연 시간(latency)을 줄이는 것이 처리량을 늘리는 것보다 전력과 칩 면접에서 훨씬 더 많은 비용이 든다는 것을 발견했습니다.
그래서, 일반적인 해법은 대량의 스레드의 실행 처리량을 최적화하는 것입니다.
이러한 설계는 메모리 채널과 산술 연산이 긴 지연시간(long-latency)를 갖게 함으로써 칩 공간과 전력을 절약하게 합니다. 칩 설계자들은 이렇게 절약한 공간과 전력을 사용하여 총 연산 처리량을 증가시킬 수 있습니다.
GPU를 사용한 소프트웨어는 아마 많은 수의 병렬 스레드를 사용하여 작성될 것입니다.
하드웨어 측면에서는 많은 스레드를 사용하여 지연시간이 긴 메모리 접근이나 산술 연산을 빠르게 수행할 수 있습니다.
또한, 어플리케이션의 대역폭 요구사항을 제어하는데 소형 캐시 메모리가 제공되므로 동일한 메모리 데이터에 액세스하는 스레드들이 DRAM에 직접 액세스할 필요도 없습니다.
이러한 디자인 스타일을 throughput-oriented design이라고 하며, 개별 스레드들이 실행하는데 오래 걸리는 작업을 많은 스레드들의 총 실행 처리량을 최대화하도록 디자인됩니다.
반면에 CPU는 단일 스레드의 실행 지연 시간을 최소화하도록 설계되었고, 이러한 디자인 스타일을 일반적으로 latency-oriented design이라고 합니다.
이처럼 GPU는 병렬화된 throughput-oriented 컴퓨팅 엔진으로 설계되었으며, CPU에서 좋은 성능을 보이는 일부 태스크에 대해서는 성능이 좋지 않을 수 있습니다.
적은 수의 스레드를 사용하는 프로그램에서는 지연 시간이 짧은 CPU가 GPU보다 훨씬 높은 성능을 낼 수 있습니다.
만약 프로그램이 많은 수의 스레드를 사용하는 경우에는 연산 처리량이 높은 GPU가 CPU보다 훨씬 더 좋은 성능을 발휘할 수 있습니다.
따라서, 많은 어플리케이션은 CPU와 GPU를 모두 사용하여 순차적인 부분(sequential part)는 CPU에서 실행하고 방대한 수치연산이 필요한 부분은 GPU에서 실행합니다. 이것이 바로 NVIDIA에서 CUDA 프로그래밍 모델이 도입된 이유이며, CUDA는 프로그램에서 CPU와 GPU가 동시에 지원할 수 있도록 설계되었습니다.
2006년까지 그래픽 칩은 사용하기가 매우 어려웠습니다. 이는 프로그래머가 칩들을 프로그래밍하기 위해서 OpenGL이나 Direct3D 기술이 필요했습니다.
이러한 기술을 GPU를 사용하여 범용 프로그래밍을 한다고 하여, GPGPU라고 하는데, 이러한 API는 사용자가 실제로 프로그램을 작성할 수 있는 어플리케이션의 종료를 제한하고 소수의 숙련된 사람들이 제한된 어플리케이션에서만 제대로된 성능을 얻을 수 있어서 이러한 프로그래밍이 널리 퍼지지 못했습니다.
하지만, 2006년 11월에 CUDA가 발표되면서 모든 것들이 바뀌었는데, NVIDIA는 병렬 프로그래밍을 쉽게하기 위해서 소프트웨어의 변경뿐만 아니라, 실리콘 면적을 할당하고 추가적인 하드웨어도 칩에 추가되었습니다. G80과 후속 칩을 사용한 병렬 컴퓨팅에서 CUDA 프로그램은 더 이상 그래픽스 인터페이스를 사용하지 않습니다.
대신 실리콘 칩에 새롭게 추가된 범용 병렬 프로그래밍 인터페이스가 CUDA 프로그램의 요청을 처리합니다. 뿐만 아니라, 소프트웨어의 모든 계층이 다시 제작되어서 개발자에게 익숙한 C/C++ 프로그래밍 도구를 사용할 수 있게 되었습니다.
Architecture of a modern GPU
CUDA를 사용할 수 있는 일반적인 GPU의 high-level의 구조는 다음과 같습니다. (간단하게 나타낸 아키텍처입니다.)
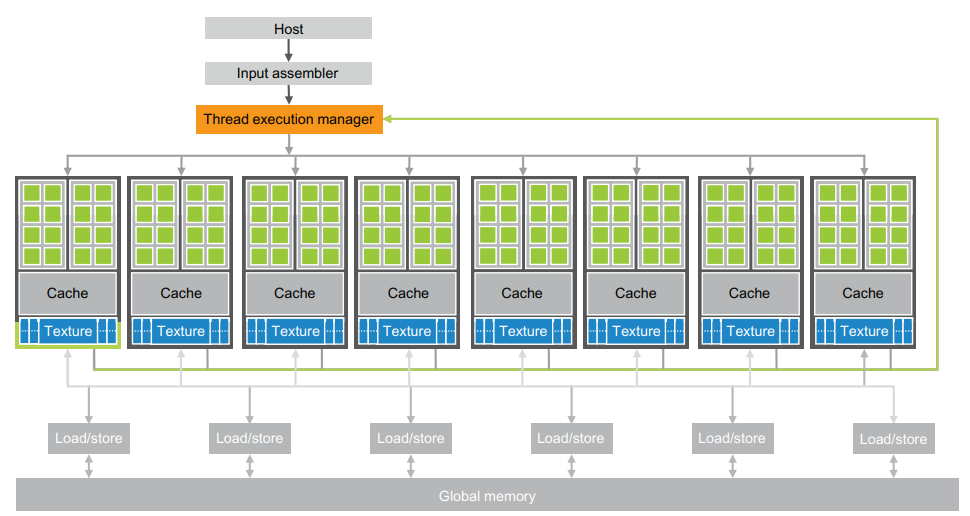
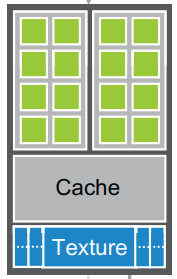
GPU는 고도로 스레드화 되어있는 스트리밍 멀티프로세서(Streaming Multiprocessors: SMs)의 배열로 구성되어 있습니다. 아래 이미지에는 2개의 SM이 빌딩 블록(building block)을 구성하고 있는 모습입니다. 이 빌딩 블록을 구성하는 SM의 수는 GPU 세대마다 다릅니다.
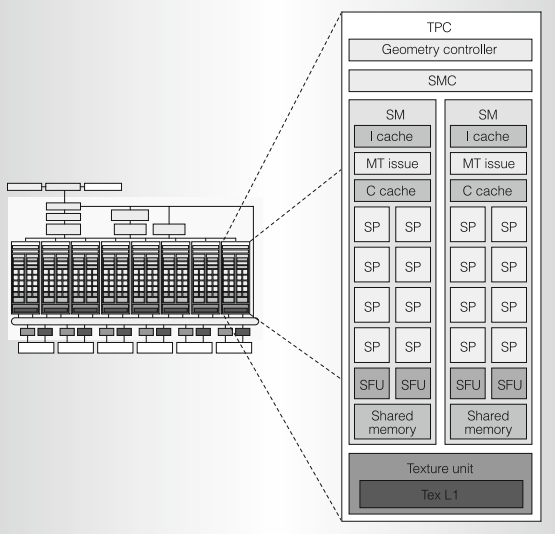
각 SM은 여러 개의 스트리밍 프로세서(Streaming Processors: SPs)를 가지고 있고, SPs는 control logic과 instruction cache를 공유합니다. 아래 이미지는 위 이미지를 조금 더 자세히 나타낸 것입니다. (Tesla Architecture)
SP는 AMD GPU에서 사용하는 용어이며, NVIDIA에서는 SP가 아닌 CUDA Core라고 부릅니다.
GPU는 SM에서 스레드를 각 SP에 할당하여 작업을 수행하게 됩니다.
GPU는 현재 Global Memory(전역 메모리)라고 하는 수 기가바이트의 GDDR(Graphics Double Data Rate), SDRAM과 함께 구성됩니다. 이 GDDR SDRAMs는 그래픽스를 위한 프레임 버퍼 메모리이며, CPU 마더보드에 있는 시스템의 DRAM과는 다릅니다.
그래픽 어플리케이션에서 이 메모리는 비디오 이미지와 3D 렌더링을 위한 텍스처(Texture) 정보를 저장합니다. 연산에 사용될 경우에는 일반적인 시스템보다 다소 긴 지연시간(latency)를 갖지만, 매우 높은 대역폭(bandwidth)를 갖는 off-chip 메모리의 역할을 합니다. 대규모 병렬 어플리케이션의 경우에 높은 대역폭은 긴 지연시간을 커버할 수 있습니다.
사실, 위 이미지들만으로 GPU 구조에 대해 자세히 알아보기는 조금 힘들 것 같습니다.
이번 포스팅에서는 GPU 구조가 대략 이렇게 생겼고, 수 많은 프로세서들이 존재하고, 이렇게 고도로 스레드화 되어 있어서 수천 개, 수만 개의 스레드를 병렬로 수행할 수 있구나 정도로만 이해하고 넘어가려고 합니다.
따라서, 자세한 GPU 구조에 대해서는 좀 더 자세하게 알아보는 시간을 따로 가져보는 시간이 필요할 것 같습니다.
특히, NVIDIA GPU의 스레드 계층은 하드웨어 계층과 밀접하게 관련이 있어서, CUDA에 대한 기본적인 내용들을 알아보고 그 이후에 아키텍처에 대해 조금 더 살펴보도록 하겠습니다 !