2023. 2. 10. 14:57ㆍmachine learning
ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)는 text summarization, machine translation과 같은 generation task를 평가하기 위해 사용되는 대표적인 Metric입니다.
본 글의 내용은 ROUGE score에 관한 논문인 https://aclanthology.org/W04-1013/를 참고하여 작성되었습니다.
Machine translation에서 주로 사용하는 BLEU가 n-gram Precision에 기반한 지표라면,
ROUGE는 이름 그대로 n-gram Recall에 기반하여 계산됩니다.
우선 N-gram에 대한 ROUGE-N은 다음과 같습니다.

위의 식은 reference summary(정답 summary)와 생성된 summary사이의 n-gram recall을 의미합니다.
Variations
ROUGE는 다양한 Variation이 존재하게 됩니다.
1) ROUGE-N
앞서 설명드린 N-gram recall 입니다.
ex) ROUGE-1 : unigram
정답문장: "한화는 10 년 안에 우승 할 것이다."
생성문장: "두산은 3 년 안에 우승 할 것이다."

ex) ROUGE-2 : bigram
정답문장: "한화는 10 년 안에 우승 할 것이다."
생성문장:"한화는 10 년 안에 절대 우승 못 할 것이다. "

2) ROUGE-L
Longest Common Subs equence
가장 긴 Sequence의 recall을 구합니다. Sequence는 이어지지 않아도 됩니다.
정답문장 "한화는 10 년 안에 우승 할 것이다."
생성문장:"한화는 10 년 안에 절대 우승 못 할 것이다. "

생성된 문장의 예시와 정답문장이 완전히 일치하지는 않지만, 떨어져 있는 Sequence 형태로 정답문장과 일치하기 때문에 1의 ROUGE-L score를 얻을 수 있습니다.
3) ROUGE-W
Weighted Longest Common Subsequence
ROUGE-W는 ROUGE-L의 방법에 더하여 연속적인 매칭(consecutive matches)에 가중치를 주는 방법입니다.

ROUGE-L의 관점에서는 Y_1과 Y_2의 결과가 같지만,
ROUGE-W의 관점에서는 consecutive matches로 이루어진 예시인 �1이 더 우수한 결과가 됩니다.
4) ROUGE-S
Skip-Bigram Co-Occurrence Statistics
skip-gram 방식과 같이, 최대 2칸(bigram) 내에 위치하는 단어 쌍의 recall을 계산합니다. skip-gram의 특성상 이어지지 않아도 되므로 상대적으로 거리에 영향을 덜 받습니다.
정답문장 : "류현진의 포심 패스트 볼은 빠르지 않지만 매우 정교하다."
생성문장 : "류현진의 투심 패스트 볼은 느리지만 매우 정확하다."

5)ROUGE-SU
Extension of ROUGE-S
ROUGE-S는 동시에 출현하는 word pair가 하나도 겹치지 않을 시 0이 됩니다.
하지만 아래 예시의 경우 어순을 바꿨을 뿐, 같은 의미에 문장임에도 ROUGE-S가 0이 되어버립니다.
정답문장 : 류현진이 공을 던졌다.
생성문장 : 던졌다 공을 류현진이
ROUGE-SU는 Unigram을 함께 계산하여 이를 보정해 줍니다.
정답문장 : ((류현진,공), (류현진,던졌다), (공,던졌다), 류현진, 공, 던졌다)
생성문장 : ((던졌다,공), (던졌다,류현진), (공,류현진), 류현진, 공, 던졌다)

6)ROUGE-N-precision
ROUGE-N-precision은 recall이 아닌 precision을 사용하여 ROUGE를 계산하는 방법입니다.
따라서 분모는 생성된 문장의 n-gram 수를 계산합니다.

BLEU와 매우 유사하다고 생각하실 수 있는데,
BLEU는 제약이 존재하며 다양한 N-gram(1~4)의 기하평균을 통해 계산됩니다.

BLEU에 대한 자세한 설명은 아래의 글을 참고 부탁드립니다.
BLEU(bilingual Evaluation Understudy) score
BLEU BLEU(bilingual Evaluation Understudy) score는 input과 output이 모두 sequence로 이루어져 있는 경우 사용하는 지표로서 machine translation과 같은 generation task에 주로 사용됩니다. $$BLEU = min(1,..
supkoon.tistory.com
7)ROUGE-N-f1
ROUGE-N-f1은 기존의 f1 score와 같이 ROUGE-N-recall과 ROUGE-N-precision의 조화평균으로 구할 수 있습니다.

Evaluations of ROUGE
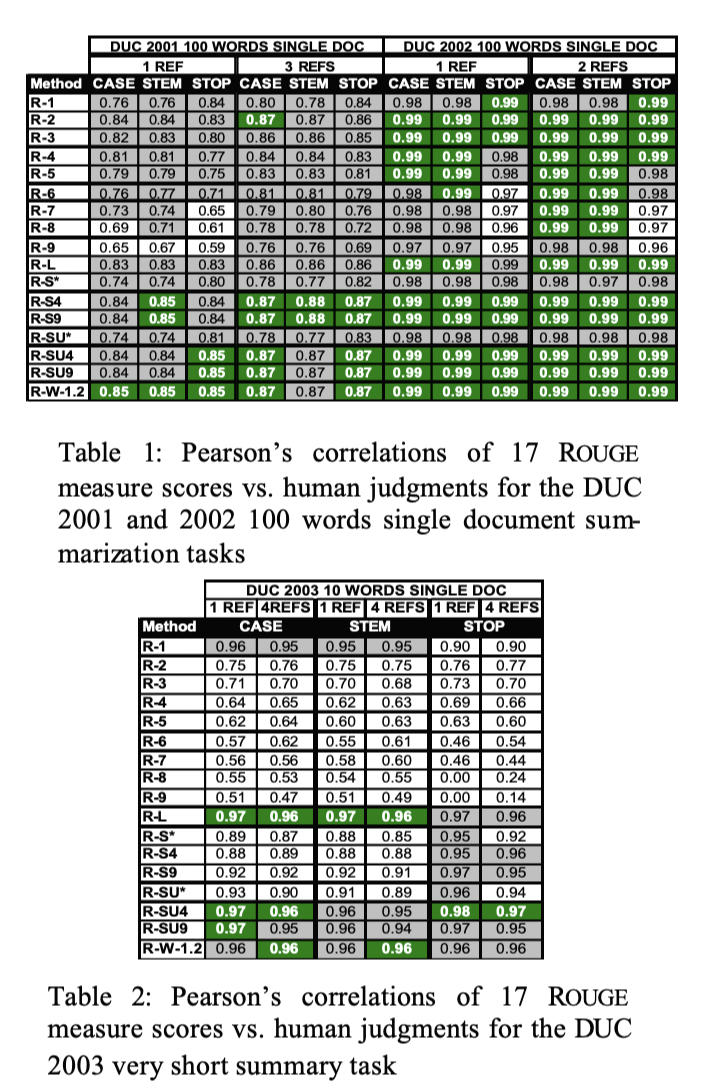
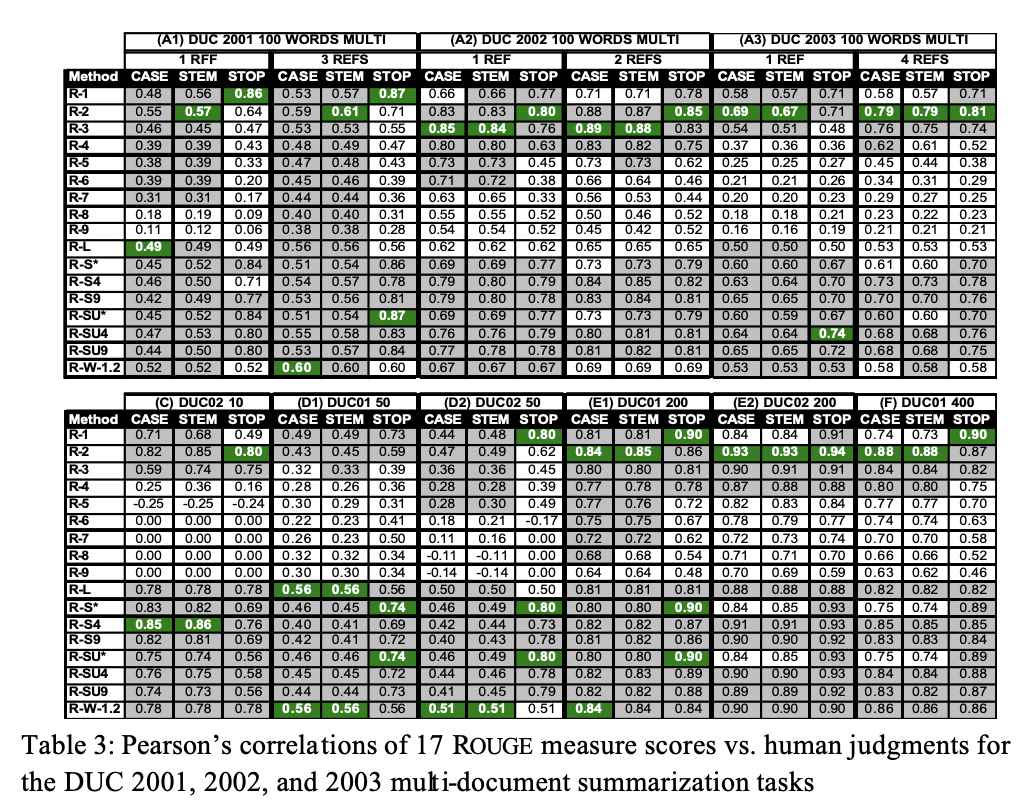
ROUGE가 Summarization과 같은 고 수준의 NLP task 지표로 쓰이는 이유는 다음과 같습니다.
각각의 표에서 ROUGE score가 대체로 인간의 판단과 양의 상관관계를 보임을 확인할 수 있습니다.
또한 ROUGE는 다양한 길이의 Sequence에서 stability and reliability를 갖추고 있습니다.
감사합니다.
'machine learning' 카테고리의 다른 글
| Transformer로 한국어-영어 기계번역 모델 만들기 (0) | 2023.02.17 |
|---|---|
| 머신러닝 훈련데이터, 테스트와 검증 데이터의 필요조건 (0) | 2023.02.10 |
| 문서요약 시 성능 문제 개선 주제 (0) | 2023.02.10 |
| 대용량 문서요약 (Multi / Long Document summarization) (0) | 2023.02.10 |
| 생성요약(Abstractive summary) vs 추출요약(extractive summary) (0) | 2023.02.10 |