Kubeflow Pipelines 란 무엇인가
2023. 1. 13. 15:10ㆍmachine learning
728x90
반응형
Kubeflow Pipelines 란 무엇인가
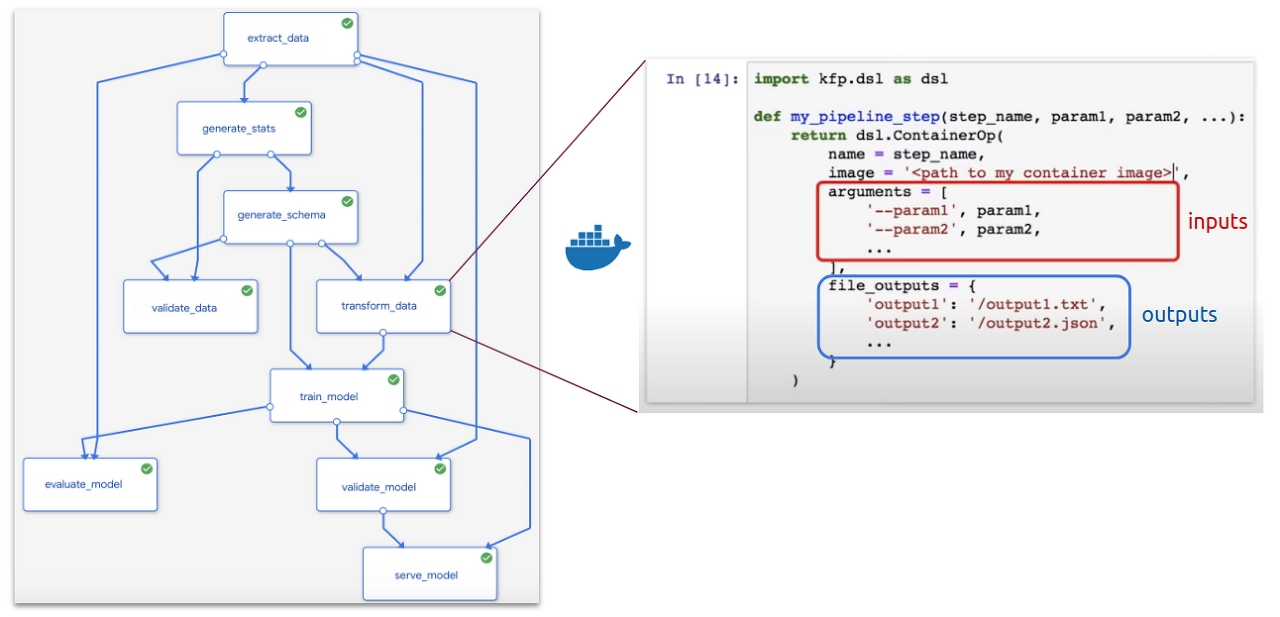
- 파이프라인은 머신러닝 워크플로우의 코드화된 표현 으로 첫 번째 이미지에 묘사된 연속된 단계들과 유사하고 워크플로우의 컴포넌트들과 그 것들 각각의 의존성을 포함
- 보다 구체적으로, 파이프라인은 각 노드에 컨테이너화된 프로세스가 있는 방향성 비순환 그래프(DAG)이다
- 하나의 블록으로 표현되는 각각의 파이프라인 컴포넌트는 도커 이미지로 패키징된 독립적인 코드 조각
- 입력과 출력을 포함하고 파이프라인에서 한 단계를 수행
- 예를 들면 위 파이파프라인에서 transform_data 단계는 extract_data 와 generate_schema 단계의 출력으로 생산되는 인수들을 필요로하고 그 출력은 train_model 의 의존성이다
- ML 코드는 다음과 같은 구성 요소로 랩핑 됨
- 매개변수 지정 - 대시보드에서 편집 가능하고 모든 실행 시 설정가능
- persistent volumes 연결 - 추가하지 않으면 어떤 이유로 노트북이 종료되는 경우 모든 데이터를 잃게됨
- artifact 가 생성 되도록 명시 - 그래프, 테이블, 선택된 이미지, 모델 - 결국 Kubeflow 대시보드의 Artifact Store 에 편리하게 저장됨
- 마지막으로 파이프라인을 실행할 때 각 컨테이너는 이제 Kubernetes 스케줄링에 따라 종속성을 고려하여 클러스터 전체에서 실행됨

- 이 컨테이너화된 아키텍처는 워크플로우가 변경될 때 컴포넌트들을 간단히 재사용, 공유, 교체할 수 있게한다
- 파이프 라인을 실행 한 후 Kubeflow 대시보드에서 파이프 라인 UI 의 결과를 탐색하고, 매개 변수를 디버그하고, 조정하고, 더 많은 “실행"을 생성 할 수 있다
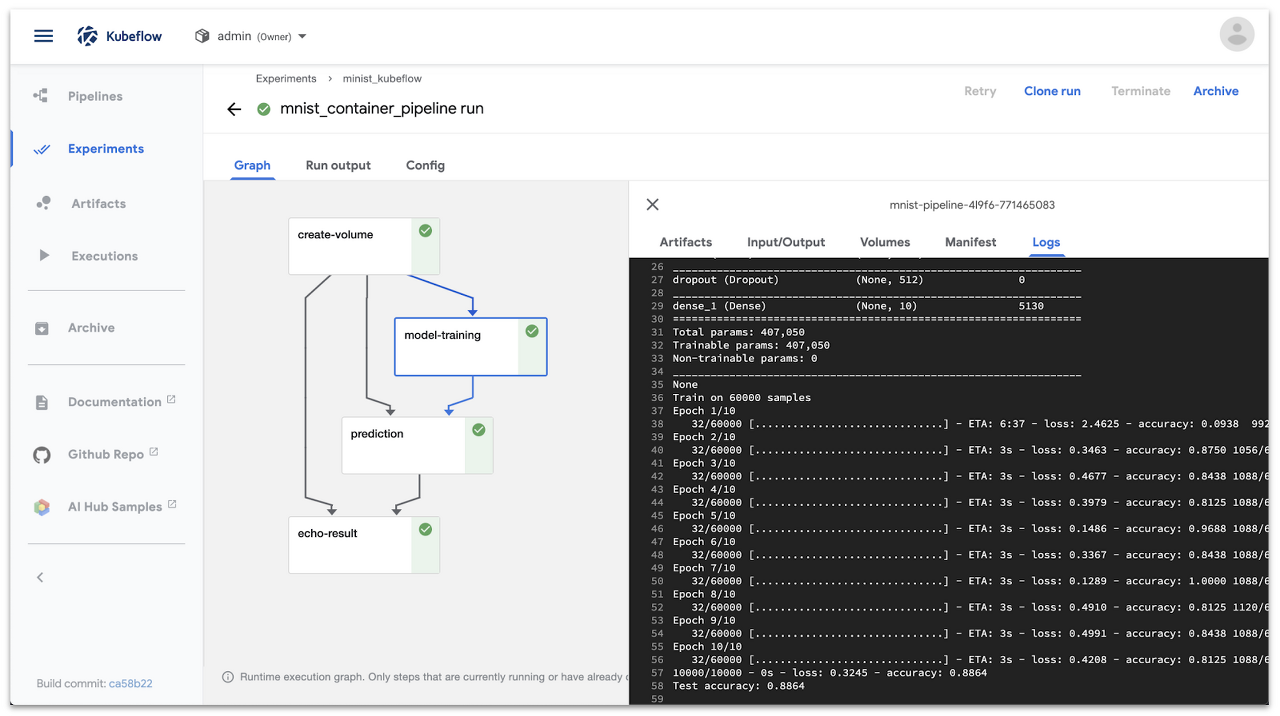
Kubeflow Pipelines 워크 플로우 구축
1. Kubeflow Pipelines SDK 시작
SDK 설치
pip install --user --upgrade kfp
경량 컴포넌트 생성
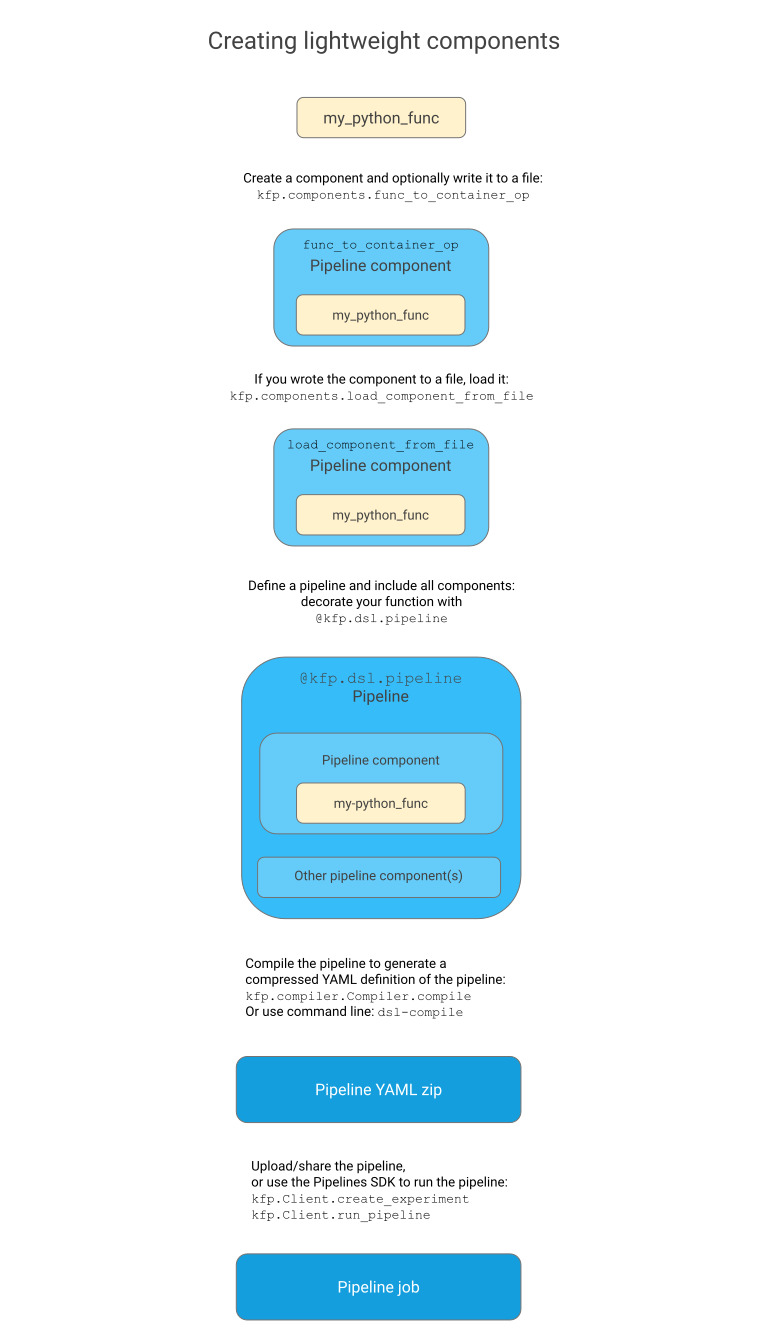
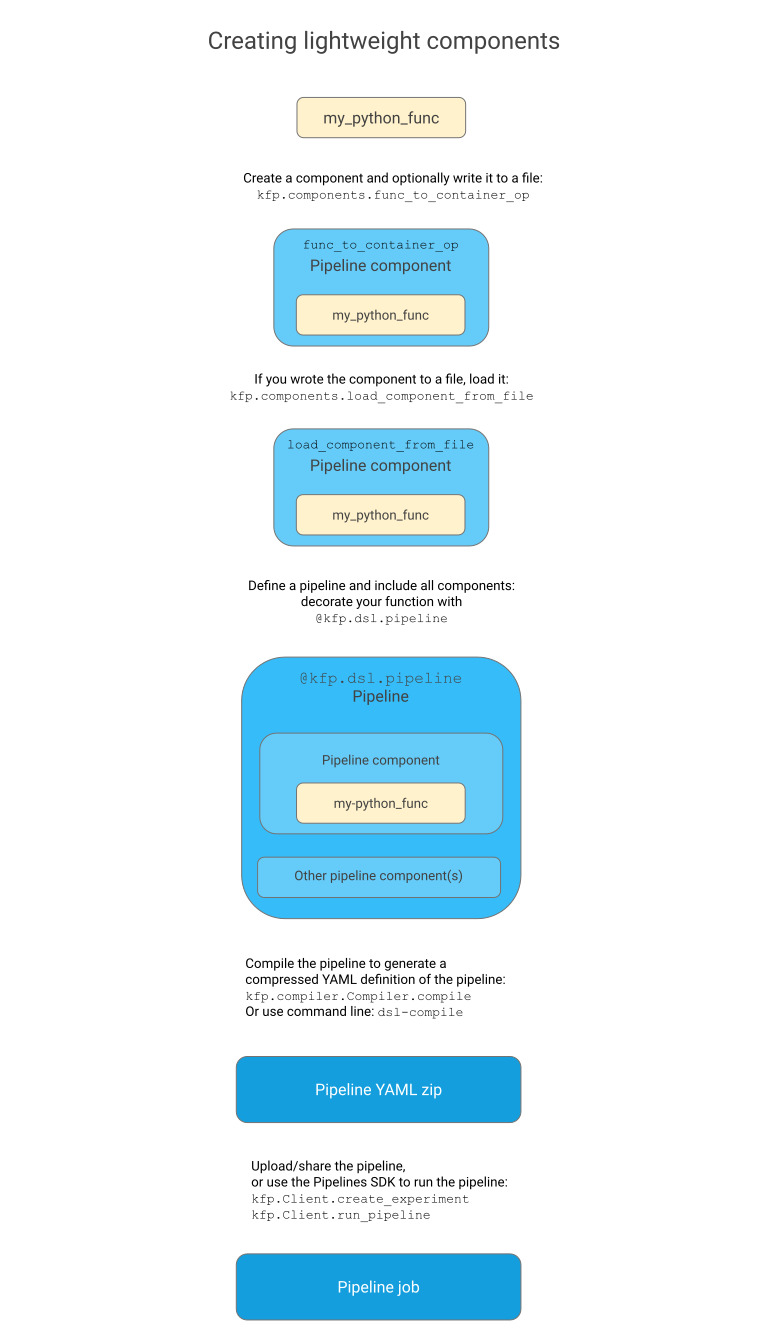
2. Python 함수를 컨테이너 구성 요소로 변환
- Kubeflow Python SDK를 사용하여 Python 함수를 정의한 뒤 func_to_container_op를 사용하여 변환하여 경량 컴포넌트를 빌드
- 컨테이너 내부에 Python 코드를 패키징하려면 논리적 단계를 포함하는 표준 Python 함수를 파이프라인에 정의. 이 경우 여기에는 train 및 predict 두 가지 함수를 정의하였음
- train 컴포넌트는 학습하고, 평가하고, 모델을 저장
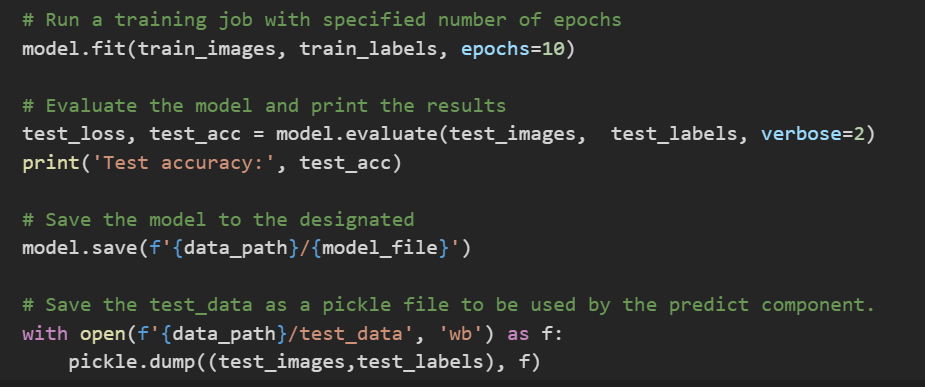
- predict 컴포넌트는 모델을 가져온 뒤 테스트 데이터셋에서 이미지를 예측
# Grab an image from the test dataset.
img = test_images[image_number]
# Predict the label of the image.
predictions = probability_model.predict(img)
- func_to_container_op 메소드를 이용하여 이 함수들을 컨테이너 컴포넌트들로 변환한다

3. Kubeflow Pipeline 정의
- Kubeflow는 YAML 템플릿을 사용하여 정의 된 Kubernetes 리소스를 사용한다. Kubeflow Pipelines SDK를 사용하면 YAML 파일을 수동으로 조작하지 않고도 코드 실행 방식을 정의 할 수 있다.
- 컴파일 타임에 Kubeflow는 파이프 라인을 정의하는 압축 된 YAML 파일을 생성한다. 이 파일은 나중에 재사용하거나 공유 할 수 있으므로 파이프 라인을 확장 가능하고 재현 할 수 있다.
- Kubeflow Pipelines API 용 클라이언트 라이브러리가 포함 된 Kubeflow 클라이언트를 시작 하여 Jupyter 노트북에서 실험을 추가로 만들고 해당 실험 내에서 실행할 수 있다.
- client = kfp.Client(host='Pipeline 서버 주소')
- Kubeflow 대시 보드에 시각화 될 파이프 라인 이름과 설명을 정의한다.

- 다음으로, 공급 될 인수를 추가하여 파이프 라인을 정의한다.
- 다음의 경우 데이터가 기록 될 경로, 모델이 저장 될 파일, 테스트 데이터 세트의 이미지 색인을 나타내는 정수를 정의한다.

4. 영구 볼륨 생성
- 이해해야 할 추가 개념 중 하나는 영구 볼륨 의 개념이다.
- 영구 볼륨을 추가하지 않으면 어떤 이유로 노트북이 종료되면 모든 데이터가 손실된다.
- Kubeflow Pipelines SDK를 사용하면 VolumeOp 객체를 사용하여 영구 볼륨을 생성 할 수 있다 .

- VolumeOp 매개 변수는 다음과 같다.
- name : UI에서 볼륨 생성 작업에 대해 표시되는 이름
- resource_name : 다른 리소스에서 참조 할 수있는 이름
- size : 볼륨 클레임의 크기
- 모드 : 볼륨 에 대한 액세스 모드
5. 파이프 라인 컴포넌트 정의
- 컨테이너 에서 파이프라인 컴포넌트를 정의하는 객체 인 ContainerOp 를 사용하여 이를 수행 .
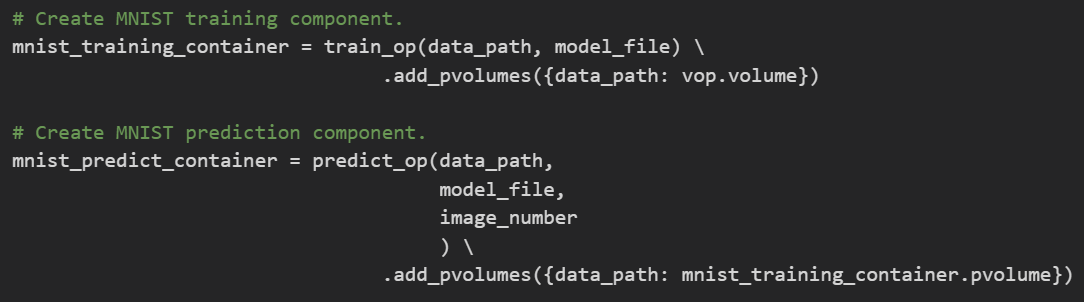
- train_op 및 predict_op 컴포넌트는 원래 파이썬 함수에서 선언 된 인수를 취한다.
- 함수가 끝나면 VolumeOp 를 경로 dictionary 와 함께 연결하고 실행 전에 컨테이너에 마운트할 영구 볼륨을 연결한다
- train_op 는 pvolumes dictionary 에 vop.volume 값을 사용하지만 다른 컴포넌트들은 새로 만드는 대신 이전 ContainerOp 의 볼륨을 사용한다
- 이것은 본질적으로 Kubeflow에 의도 된 작업 순서를 알려준다. 결과적으로 Kubeflow는 이전 Container_Op 실행이 완료된 후에만 해당 볼륨을 마운트한다.

- 최종 print_prediction 구성 요소는 약간 다르게 정의된다. 여기에서 사용할 컨테이너를 정의하고 런타임에 실행할 인수를 추가한다.
- 이는 ContainerOp 객체를 직접 사용하여 수행된다 .
- ContainerOp 매개 변수는 다음과 같다.
- name : 런타임 중 구성 요소 실행에 대해 표시되는 이름.
- image : 사용할 Docker 컨테이너의 이미지 태그
- pvolumes : 실행 전에 컨테이너에 마운트 할 경로 및 관련 영구 볼륨의 dictionary
- arguments : 런타임에 컨테이너에서 실행할 명령
6. 컴파일 및 실행
- 마지막으로 노트북은 파이프 라인 코드를 컴파일하고 실험 내에서 실행한다.
- 실행 및 실험 (실행 그룹)의 이름이 노트북에 지정된 다음 Kubeflow 대시 보드에 표시된다.
- 이제 노트북 링크 run 을 클릭하여 Kubeflow Pipelines UI에서 실행중인 파이프 라인을 볼 수 있다.



자료 출처
728x90
반응형
'machine learning' 카테고리의 다른 글
| 파라미터와 하이퍼파라미터의 개념의 차이 (0) | 2023.02.09 |
|---|---|
| 텍스트 유사도, 두 단어 혹은 두 문장이 주어졌을 때, 유사도를 어떻게 측정할 수 있을까? (0) | 2023.01.27 |
| 쿠버네티스 + mlflow(머신러닝) = Kubeflow 란 무엇인가 (0) | 2023.01.13 |
| 딥러닝 이용한 검색고도화 기획안2 : click model (0) | 2023.01.13 |
| 딥러닝을 이용한 검색 고도화 기획안1 : ColBERT를 이용한 검색결과 랭킹모델 재고 (0) | 2023.01.13 |