2022. 5. 14. 15:23ㆍ검색
질의확장 개념
참조:
https://jiwondev.tistory.com/57?category=852827
#10 적합성 피드백 (Relevance Feedback)
앞에서 검색모델의 기본요소(TF, IDF, Document Length, N) 불린 모델 (문제점을 해결한 확장 불리언 모델은 배우지 않았음) 벡터 공간모델(cos 유사도, TF-IDF 데이터모델) 확률 모델(BM25) 언어 모델(JM, diric
jiwondev.tistory.com
앞에서
검색모델의 기본요소(TF, IDF, Document Length, N)
불린 모델 (문제점을 해결한 확장 불리언 모델은 배우지 않았음)
벡터 공간모델(cos 유사도, TF-IDF 데이터모델)
확률 모델(BM25)
언어 모델(JM, dirichlet)
정보검색 성능평가(P, R, F1, Pre, R-pre NDCG)
이렇게 정보검색의 기본요소들을 간략화 하여 배웠습니다.
이제 이렇게 만든 정보검색모델 (IR Model)의 성능을 향상시키는 '적합성 피드백'에 대해 배워봅시다.
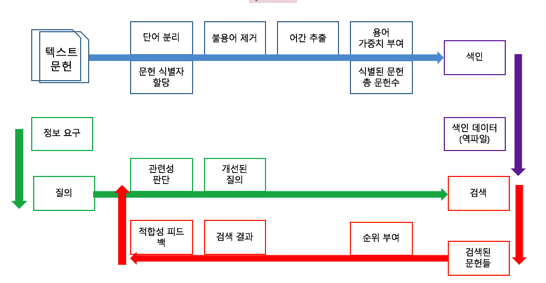
# 사용자 질의의 불완전, 불충분성
검색모델에서 사용자는 SQL을 이용하여 질문하는게 아니라, 자연어로 질의문을 작성합니다. 즉, 같은 질문 내용이라도 사람마다 질의문의 구성이 다릅니다. 즉 사용자 질의의 불완전, 불충분성 때문에 검색성능이 저하 될 수 있습니다.
이 문제를 해결하는 방법 중 하나가 적합성 피드백을 이용하여 해결합니다.

# Relevance Feedback(적합성 피드백)
질의에 대한 적합성을 의미합니다.
검색모델에서 '질의 문에 대한 정보'만 사용하여 문서의 유사도 순위를 매겼습니다.
적합성 피드백은 이에 추가로 '이미 가지고 있던 적합문서의 정보'를 이용하여 성능을 향상시키는 방법입니다.
사용자 적합성 피드백 : 사람이 직접 적합성을 검사하고 피드백합니다.
의사 (pseudo) 적합성 피드백 : 1차 검색에서 상위 검색된 상위k개의 문서를 적합하다고 가정하여 피드백합니다.
(부적합 문서는 반대로 하위 10개)

# 적합성 피드백의 주요 단계

# 적합성 피드백의 핵심
각 문서가 벡터 그래프값을 가진다고 생각하면, [적합문서, 부적합문서]정보를 이용해 질의문을 원하는 위치로 바꾸는게 적합성 피드백의 핵심입니다.

이는 각 벡터 그래프 값의 합과 차를 이용하여 질의문을 수정 할 수 있습니다.
적합문서 또는 부적합문서(D)를 이용해 질의문(Q)의 값을 벡터합, 벡터차로 원하는 위치로 바꿉니다.

왼쪽 (적합문서, 벡터합셈) 오른쪽(부적합문서, 벡터뺼셈)
# 로치오 알고리즘
이를 이용한 대표적인 방법이 '로치오 알고리즘' 입니다.
실제 검색모델에서는 '적합문서'가 한개가 아닌 여러개라서
각 벡터들의 중심점을 계산하여 벡터합(적합문서), 벡터차(부적합문서)를 이용하여 질의문을 변경하는 방법입니다.

벡터의 중심은 어떻게 구하나요?
쉽습니다. 그냥 더해서 평균 내면 그게 중심 벡터입니다.
1차원 좌표평면에서 중심값은, 각 점들을 더해서 개수로 나눠주면 됩니다.



참고로 적합문서, 부적합문서는 사용자가 직접 찾아서 데이터로 만들고, 의사 (pseudo) 적합성 피드백의 경우 상위 k개를 적합, 하위 k개를 부적합으로 보고 계산합니다.
다만 실제 시스템에서는 대부분 '긍정피드백'만 사용합니다.
왜 긍정피드백(적합문서)만 사용할까요?
긍정피드백은 정확하지 않아도 비슷한 질의문 벡터를 한 곳으로 모아주지만
부정피드백은 정확하지 않으면 그냥 질의문 벡터를 흩트려 놓을 뿐입니다.
Q { 사자 } 에서 긍정피드백은 '무엇이 사자를 나타내는지'를 의미하고
Q { 사자 } 에서 부정피드백은 '사자가 아닌 모든 것'을 의미합니다.
부정피드백에서 도움이 될려면 [질의문이 아닌 모든 피드백]을 골고루 주어여합니다. 이는 사실상 말이 되지 않으므로 대부분의 시스템에서 사용하지 않습니다.
물론 절대적인 정답은 없습니다. 정보검색 시스템에서 부정피드백을 사용하는 더 나은 방법이 있다면 바뀔수도 있는거죠
#예제
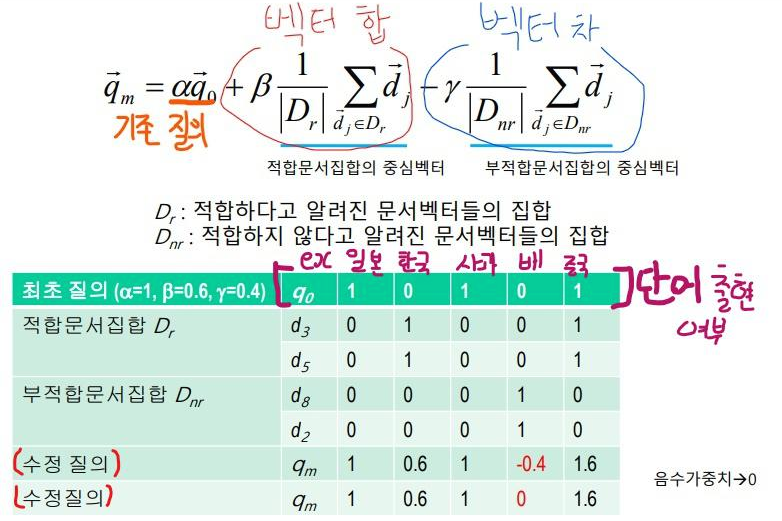
로치오 알고리즘을 사용하여 질의문을 수정하면 아래 그림과 같습니다.
[기존 질의], [적합문서의 중심벡터합], [부적합문서의 중심벡터차]에 각각 가중치를 붙여 계산하면 됩니다.
재밌는 건 단어의 가중치가 0에서 1로 변하기도 한다는 점입니다. (ex 질의문 : 한국수도, '서울' 0->1로 변경)
참고로 이런 식으로 질의가 늘어나는 현상을 적합성 피드백의 Query Extension(질의 확장)이라고 부릅니다.
또한 질의 용어의 가중치를 변경하는 것(ex 1->2.4)을 질의용어의 차별화라고 부르기도 합니다.
한줄로 요약하면 '질의확장'과 '질의용어의 차별화'를 통해 검색 시스템이 향상된다. 라고 합니다.
# Ide_Regular 알고리즘
검색성능을 높일 수 있는 수식이면, 굳이 벡터 평균값이 아니여도 괜찮습니다.
대표적으로 Ide_Regular 알고리즘은 평균이 아닌 각 벡터의 합을 이용하여 질의문을 피드백합니다.

# Ide_Dec_Hi 알고리즘
Ide_Regular에서 적합은 벡터의 합을, 부적합 문서는 최상위 1개만 사용하는 방법입니다.

'검색' 카테고리의 다른 글
| 검색엔진(Search Engine)의 현황 및 구동원리 (0) | 2022.05.14 |
|---|---|
| 정보검색 - 회고 (0) | 2022.05.14 |
| 정보검색 성능 평가 (2/2) - MAP, Pre@K, R-pre, NDCG (0) | 2022.05.14 |
| 정보검색 성능 평가 (1/2) - P, R, F1, PRC (0) | 2022.05.14 |
| 정보검색 - 검색모델(벡터 모델) (0) | 2022.05.14 |